IODA File Formats¶
Overview¶
IODA can read files in the following formats:
HDF5
ODB
BUFR
Script
and write files in the following formats:
HDF5
ODB
IODA currently provides two reader implementations: the original reader (which is not io pool based) and a new io pool based reader. The plan is to phase out the original (non io pool based) reader and replace it with the io pool based reader.
IODA provides one writer implementation which is io pool based.
Io pool based reading and writing means that a small number of tasks in the ObsSpace main communicator group are designated as io pool members and only these tasks handle file IO operations. All of the data belonging to non io pool members is handled with MPI data transfers.
The flow of the io pool reader is show in Fig. 21 below.
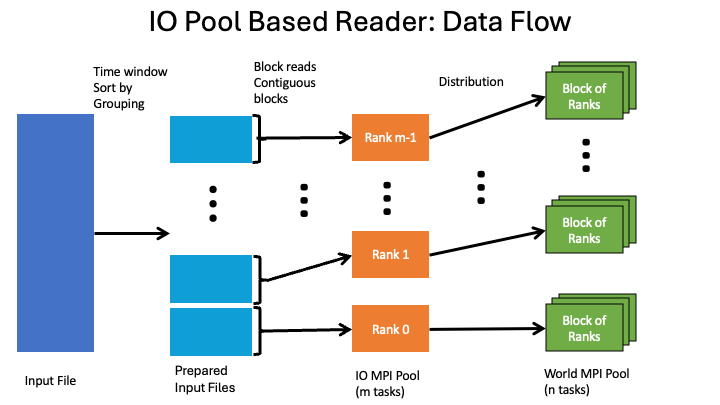
Fig. 21 Data flow for the IODA io pool based reader¶
The steps moving from left to right are to prepare a set of input files from the original file, read those files into corresponding io pool ranks, and then distribute to the remaining ranks using MPI data transfers. The prepared file set is constructed with the locations rearranged for streamlining the subsequent MPI data transfers. Each file in the prepared file set contains only the locations destined for the given io pool rank and its assigned non io pool ranks. In addition, the locations are grouped in contiguous blocks where each block represents the locations that get distributed to each rank (i.e., the io pool rank and its assigned non io pool ranks).
Note that the io pool based writer data flow essentially is the reverse of that shown in Fig. 21, with the exception that the output file is directly written by the io pool ranks since there is no need to rearrange the locations in the writer flow.
Io Pool Configuration¶
Controls for the io pool feature are grouped into the obs space.io pool YAML configuration section, and apply to any of the specific file types.
Note that there is only one io pool specification for a given obs space configuration meaning that the configuration is shared by the reader and writer.
With the io pool a maximum size is specified (default is 4 tasks) using the obs space.io pool.maximum pool size specfication.
The io pool size is set to the minumum of the communicator group size and the specified maximum pool size.
Here is an example showing how to change the maximum pool size from the default of 4 to 6.
obs space:
io pool:
max pool size: 6
Non Io Pool Based Reading¶
Currently, the original reader is selected by default so no change is needed in the YAML to select this reader.
Therefore, no need to add an obs space.io pool configuration section in the YAML for the reader.
Io Pool Based Reading¶
The obs space.io pool.reader name YAML specification allows the user to select the io pool based reader by setting the reader name to “SinglePool” as shown below.
obs space:
io pool:
reader name: SinglePool
The io pool based reader can operate in two modes denoted “internal” and “external”.
“Internal” refers to having the IODA reader create the prepared file set during its initialization step.
In other words, the prepared input file set is created on the fly during the execution of the DA job.
“External” refers to having an external process, run prior to the DA job, create the prepared file set, and is accomplished using the ioda-buildInputFileSet.x application.
Internal mode¶
Internal mode is the default so it is not required to specify this in the YAML configuration. However, the internal mode requires a work directory that is expected to be provided, and specified in the YAML, from external (to the DA job) means such as the workflow. The IODA reader expects the work directory to exist, and expects the external means to clean up the work directory (i.e., remove the intermediate input file set) if that is desired. Here is an example configuration:
obs space:
obsdatain:
engine:
type: H5File
obsfile: Data/testinput_tier_1/sondes_obs_2018041500_m.nc4
io pool:
reader name: SinglePool
work directory: path/to/the/work/directory
Let’s say that a workflow is being used. Then the workflow is expected to create the work directory (path/to/the/work/directory), give it the proper write permissions so that the reader can create the input file set, and optionally clean up after the DA job finishes. The IODA reader will check for the existence of the work directory, and if it is missing will throw an exception and quit.
The IODA reader will name the input file set files based on the file name given in the obsdatain.engine.obsfile specification.
In this example with an io pool size of 4, the input file set will be created as:
path/to/the/work/directory/sondes_obs_2018041500_m_0000.nc4
path/to/the/work/directory/sondes_obs_2018041500_m_0001.nc4
path/to/the/work/directory/sondes_obs_2018041500_m_0002.nc4
path/to/the/work/directory/sondes_obs_2018041500_m_0003.nc4
Note that the work directory and input file set organization and naming is under the control of the workflow, and it is therefore the responsibility of the workflow to prevent file name collisions.
This can be accomplished by either using unique names in all of the obsdatain.engine.obsfile specifications, or by using unique work directory paths for each of the different obs space specifications.
The former is typically the situation for a workflow, whereas the latter is being used to prevent collisions in the IODA tests (which share common input files).
External mode¶
In the external mode, two configurations need to be specified: one for the standalone application, and the other for the IODA reader during the DA run. For the examples shown below, let’s say that the DA run is planned to be run with 100 MPI tasks, and the io pool is to consist of 6 MPI tasks. Note how these two configurations need to be consistent with respect to the planned MPI allocation (i.e, in this case 6 tasks in the io pool and 100 tasks overall).
Standalone Application Configuration
The standalone application is run using the ioda-buildInputFileSet.x application and takes the usual arguments for an oops::Application executable:
# usage string is: ioda-buildInputFileSet.x config-file [output-file]
# where config-file contains the YAML specifications, and output-file is an optional log file
ioda-buildInputFileSet.x standalone-app-config.yaml
The standalone application will perform the usual time window filtering, obs grouping and generating the MPI routing (where each location goes, but without the actual distribution) that the original and internal mode of the io pool based readers do.
Because of this, the YAML configuration for the standalone application mimics the configuration for the IODA reader to keep things consistent and familiar.
The usual obs space.obdatain configuration and obs space.io pool configurations apply.
The standalone application is specified by setting the obs space.io pool.reader name configuration to “PrepInputFiles”.
Some additional configuration is necessary to inform the standalone application of the planned target size (100 MPI tasks for this example) of the main ObsSpace communicator group in the subsequent DA job, and for the output file name.
As before, the output file name gets the io pool communicator rank numbers appended to create the unique names in the input file set.
Also, the directory portion of the output file name specification is expected to be managed by the workflow (or other external means).
Here is an example YAML configuration for the standalone application:
time window:
begin: "2018-04-14T21:00:00Z"
end: "2018-04-15T03:00:00Z"
obs space:
name: "AMSUA NOAA19"
simulated variables: ['brightnessTemperature']
channels: 1-15
obsdatain:
engine:
type: H5File
obsfile: "Data/testinput_tier_1/amsua_n19_obs_2018041500_m.nc4"
io pool:
reader name: PrepInputFiles
max pool size: 6
file preparation:
output file: "path/to/work/directory/amsua_n19_obs_2018041500_m.nc4"
mpi communicator size: 100
In this example, the communicator given to the ObsSpace constructor in the subsequent DA job is expected to contain 100 MPI tasks as mentioned above.
A work directory is implied by the directory portion of the io pool.file preparation.output file specification, and as in the internal mode case, the workflow is expected to manage that directory.
Note that the time window specification is required and must match that of the subsequent DA job. This is necessary for executing the time window filtering operation.
Only one obs space specification is accepted by the standalone application since it is expected that the workflow will submit separate jobs in parallel for each of the target ObsSpace objects, whereas allowing for multilple obs space specifications in one execution of the standalone application will force serial execution for those ObsSpace targets.
DA Job Configuration
The configuration for the subsequent DA job needs to be consistent with the configuration given to the standalone application.
This configuration needs to specify the “SinglePool” reader name, along with a new obsdatain.file preparation type specification to tell the IODA reader that the input file set was created by the standalone application.
Here is the YAML configuration for the DA job that goes with the example standalone application YAML example above.
time window:
begin: "2018-04-14T21:00:00Z"
end: "2018-04-15T03:00:00Z"
...
observations:
- obs space:
name: "AMSUA NOAA19"
simulated variables: ['brightnessTemperature']
channels: 1-15
obsdatain:
engine:
type: H5File
obsfile: "path/to/work/directory/amsua_n19_obs_2018041500_m.nc4"
file preparation type: "external"
io pool:
reader name: SinglePool
max pool size: 6
Note that the io pool.max pool size specification (6) is in accordance with the planned DA run, which will use 100 total tasks, as noted above.
Also note that the obsdatain.engine.obsfile specification for the DA job YAML, matches the io pool.output file specification for the standalone application YAML.
This will allow for the file naming (i.e., the appending of the io pool rank number) to match up between the two steps.
This coordination between the standalone application YAML and the DA job YAML is a bit cumbersome, but it is expected to be automated in a workflow so hopefully this is not too troublesome.
To help with the setting up of these configurations, the standalone application creates an additional file in the input file set with a _prep_file_info suffix (amsua_n19_obs_2018041500_m_prep_file_info.nc4 in the examples above) that holds information about what the input file set “fits” with.
In these examples the prep_file_info file will contain attributes holding the expected io pool size (6) and the expected main communicator size (100), plus variables holding information describing the io pool configuration that the input file set was built for.
These values are checked by the IODA reader in the DA flow and if these do not match up an exception, with messages indicating what is wrong, is thrown and the job quits.
Reading ODB Files in Parallel¶
To read ODB files in parallel, set the io pool reader name to NonoverlappingPool and the distribution to Identity, as shown in the snippet below:
obs space:
name: ATMS
simulated variables: [brightnessTemperature]
channels: 1-22
obsdatain:
engine:
type: ODB
obsfile: "Data/testinput_tier_1/atms.odb"
mapping file: ../share/test/testinput/odb_default_name_map.yaml
query file: ../share/test/testinput/iodatest_odb_atms.yaml
frame distribution spread: 4 # optional; 4 is the default value
distribution:
name: Identity
io pool:
reader name: NonoverlappingPool
This will cause each MPI process to read a separate subset of frames from the input ODB file. If consecutive rows with the same value in the seqno column (typically used to distinguish between e.g. different aircraft tracks, radiosonde profiles or satellite observation locations) are found in multiple frames read by different processes, the ODB reader will arrange for the contents of all these rows to be transferred to a single process.
Warning
Record grouping criteria that might assign locations associated with ODB rows with different seqnos to the same record will not automatically be respected. In other words, by default, the parallel ODB reader will not ensure that locations with identical values of the grouping variables are placed on the same MPI process.
However, if the ODB rows belonging to each record are placed next to each other in the input ODB file, then it is possible to prevent the reader from splitting them across multiple MPI processes. To this end, set the record grouping columns option in the ODB query file to the list of ODB columns by which the records are grouped; for example,
record grouping columns: - date - time - radar_beam_elevation - radar_identifier
The parallel reader will then ensure that all consecutive rows with identical values of all these columns are placed on the same MPI process.
In contrast, if the ODB rows belonging to each record are not placed next to each other – for example, locations need to be grouped into records by latitude, but ODB rows are not sorted by latitude – then there is currently no way to force the parallel ODB reader to keep such rows together. Such files need to be read serially.
Warning
Only the Identity distribution is compatible with NonoverlappingPool; an attempt to use a different one will cause an exception to be thrown.
Load Balancing Control¶
The Identity distribution keeps locations on the MPI processes on which they have been placed by the ODB reader. The resulting distribution may not be balanced very well, especially if ODB rows are ordered roughly chronologically and a lot of initial and final rows lie outside the assimilation window and are filtered out. To mitigate against this issue, by default, each process reads 4 separate “chunks” of frames located in different parts of the input file (unless the number of frames is less than four times the number of processes, in which case the number of chunks per process is reduced to ensure all processes receive approximately the same number of frames). The maximum number of chunks per process can be adjusted by setting the frame distribution spread option in the obsdatain.engine YAML section to a value different than 4. Larger values may improve load balancing but will also increase the cost of MPI communication required to ensure consecutive rows with the same seqno are not split across multiple processes.
If the number of frames in the file is less than the number of processes, some processes will not be assigned any frames to read. The NonoverlappingPool will take care to produce a valid ObsSpace in this case too (e.g. by ensuring that these processes create the same ioda variables as ones with frames assigned).
As an example, consider an input file with 15 frames. If this file is read with 2 MPI processes, each of them will by default be assigned four separate contiguous chunks of frames, as shown in the diagram below:

If the frame distribution spread is reduced from 4 to 1, each process will be assigned just a single large chunk of frames:

Conversely, if frame distribution spread is increased to 8 or more, process 0 will be assigned eight and process 1 seven chunks, each consisting of just a single frame:

If frame distribution spread is left at its default value of 4, but the number of MPI processes is increased to 5, each process will receive three chunks, since there not enough frames to form 4 × 5 = 20 chunks:

Io Pool Based Writing¶
In addition to specifying the maximum pool size, the writer pool can be configured to produce a single output file (default) or a set of output files that correspond to the number of tasks in the io pool.
In the case of writing multiple files, each MPI rank in the io pool will write its observations, plus the observations of the non io pool ranks assigned to it, to a separate file with the name obtained by inserting the rank number before the extension of the file name taken from the obs space.obsdataout.engine.obsfile option.
obs space:
...
obsdataout:
engine:
type: H5File
obsfile: Data/sondes_obs_2018041500_m_out.nc4
io pool:
max pool size: 6
write multiple files: true
In this example the writer is being told to form an io pool of no more than six pool members, and to write out multiple output files.
Note a setting of false for the write multiple files is the default and results in the writer producing a single output file containing all of the observations.
In this case, when there are 6 tasks in the io pool the output files that are created are:
Data/sondes_obs_2018041500_m_out_0000.nc4
Data/sondes_obs_2018041500_m_out_0001.nc4
…
Data/sondes_obs_2018041500_m_out_0005.nc4
The obs space.obsdataout.empty obs space action YAML configuration option is used to control the action taken
when an empty ObsSpace object is encountered during the writing process.
Valid settings include create output (default, create a corresponding empty output file) and
skip output (do not create an output file).
An empty obs space is understood to be one that contains zero locations across all MPI ranks, meaning that
if some ranks contain zero obs and other ranks contain greater than zero obs, the output file will still
be created when the skip output setting is used.
Here is an example YAML configuration that uses the skip output setting.
obs space:
...
obsdataout:
empty obs space action: "skip output"
engine:
type: H5File
obsfile: Data/sondes_obs_2018041500_m_out.nc4
io pool:
max pool size: 6
Specific File Formats¶
The following sections describe how the specific file formats are handled from the user’s point of view.
Additional Reader Controls¶
Missing File Action¶
When a missing input file is encountered, the reader can be configured to take one of two actions:
Issue a warning, construct an empty ObsSpace object, and continue execution. This action is typically applicable to operations where you want the job to forge ahead despite a missing file.
Issue an error, throw an exception, and quit execution. This action is typically applicable to research and development where you want to be immediately notified when a file is missing.
The missing file action can be specified in the YAML configuration using the missing file action keyword.
The valid values are warn or error (default), where warn corresponds the the first action and error corresponds to the second action noted above.
Here is a sample YAML section that shows how to configure the missing file action to be an error.
time window:
begin: "2018-04-14T21:00:00Z"
end: "2018-04-15T03:00:00Z"
...
observations:
- obs space:
name: "AMSUA NOAA19"
simulated variables: ['brightnessTemperature']
channels: 1-15
obsdatain:
engine:
type: H5File
obsfile: "Data/amsua_n19_obs_2018041500_m.nc4"
missing file action: error
Note that the missing file action keyword is specified in the obs space.obsdatain.engine section.
Handling Multiple Input Files¶
The IODA reader can handle multiple input files that are specified for the construction of a single ObsSpace object. The files are appended along the Location dimension to form the data loaded into the ObsSpace object, and as such have the following constraints on their layout.
The files need to contain the same set of variables.
For multi-dimensioned variables (e.g., Location X Channel), the second and higher dimensions must be specified identically in each file. For the 2D, Location X Channel example, each file must have the same number of channels all specfied with matching channel numbers.
Variables that are not dimensioned by Location must be defined identically in each file. For example, if the files contain
MetaData/channelFrequency(dimensioned by Channel), the corresponding variable in each file must be the same size and have the same values.For the file formats (ODB, BUFR) that require additional configuration beyond the paths to the input files (e.g. ODB mapping file, BUFR table path, etc.), each file needs to be readable using the same set of additional configuration.
A new keyword named obsfiles (plural) has been added to the YAML configuration, and this keyword is placed in the obs space.obdatain.engine section.
The current obsfile (singluar) keyword will continue to be accepted.
Note that the existing YAML files will contiue to read in single files as before, thus there is no need to modify existing YAML (except to specify multiple input files).
One and only one of the obsfile or obsfiles keywords must be used for the reader backends that tie to files (eg, H5File, ODB, bufr).
Here is an example HDF5 file backend YAML configuration using multiple input files.
time window:
begin: "2018-04-14T21:00:00Z"
end: "2018-04-15T03:00:00Z"
...
observations:
- obs space:
name: "AMSUA NOAA19"
simulated variables: ['brightnessTemperature']
channels: 1-15
obsdatain:
engine:
type: H5File
obsfiles:
- "Data/amsua_n19_obs_2018041500_m_p1.nc4"
- "Data/amsua_n19_obs_2018041500_m_p2.nc4"
- "Data/amsua_n19_obs_2018041500_m_p3.nc4"
Note that the file data will be appended to the ObsSpace in the order of the list of files in the obsfiles specification.
File Processing Applications¶
ioda-filterObs.x¶
The ioda-filterObs.x application provides a means to filter observation data in the situtation where a filter can be accomplished with only the observation data itself.
Examples would be thinning data using an algorithm that randomly selects a subset of the data, and throwing out unrealistic data such as negative temperature values when the units are in Kelvin.
Filters requiring additional data such as the forecast background must use the filter operators in UFO.
Currently, ioda-filterObs.x offers the following filters:
Time window filter
This filter is always applied and will reject observations that are outside of the given time window.
Receipt time filter
This filter is optional (disabled by default) and will reject observations that have a receipt time outside a given acceptance time window. The receipt time filter is enabled with a YAML
receipt time filterspecification, which contains two parameters: an accept (time) window and a variable name. The specified variable is normally expected to exist in the ObsSpace (see the optional receipt time generator option below), to be in the epoch datetime format, and to contain the receipt time for each location. The specified accept window is expected to be in the format required for an oopsutil::TimeWindow. The filter will read in the receipt time variable and for each entry in the variable, compare that to the accept window and reject locations that are outside the accept window.Note that the receipt time filter is primarily useful for contriving data from existing ioda files for demo or research purposes. In these contexts, the filter can be used to remove observations that haven’t “arrived” yet.
The receipt time filter provides an optional generator of receipt times. This generator is disabled by default (i.e., the receipt time variable is expected to exist in the input file) and can be enabled using the
generate receipt timesYAML control. The generator creates receipt times that lie within a range of delays after the corresponding observation time stamp (MetaData/dateTimevalue), and uses an algorithm that produces a somewhat uniform distribution of delays while being reproducible. Two parameters for the generator are specified in the YAML configuration: a minimum delay and a maximum delay, both expressed in seconds. The generator algorithm uses the remainder from applying a modulo operation with the observation time stamp and the range of the delay window (max delay minus min delay) to calculate a delay value within the given mininum and maximum delay specifications and adds that delay to the observation time stamp.
ioda-filterObs.x is based on oops::Application and as such takes a configuration YAML file as a required argument, plus an optional second argument that specifies a log file for saving messages from the application.
By default the application writes all of its messages to stdout and stderr.
Here is the usage for ioda-filterObs.x.
# usage string is: ioda-filterObs.x config-file [output-file]
# where config-file contains the YAML specifications, and output-file is an optional log file
ioda-filterObs.x filter-obs-app-config.yaml
In the required YAML configuration file, you must specify one time window section and one obs space section.
Note that in this case both the obs space.obsdatain and obs space.obsdataout sections must be specified.
(Normally the obs space.obsdataout section is optional.)
The specified time window will be applied to the data contained in the input file(s) given in the obs space.obsdatain section and the results are written to the output file given in the obs space.obsdataout section.
Here is an example YAML configuration for reading a single input file and applying only the time window filter.
---
time window:
begin: "2024-01-10T00:00:00Z"
end: "2024-01-10T06:00:00Z"
obs space:
name: "Single File Input"
simulated variables: ['airTemperature']
obsdatain:
engine:
type: H5File
obsfile: "Data/sonde_obs_example.nc4"
obsdataout:
engine:
type: H5File
obsfile: "FilteredData/sonde_obs_example.nc4"
Here is a similar example except for reading multiple input files.
---
time window:
begin: "2024-01-10T00:00:00Z"
end: "2024-01-10T06:00:00Z"
obs space:
name: "Multiple File Input"
simulated variables: ['airTemperature']
obsdatain:
engine:
type: H5File
obsfiles:
- "Data/sonde_obs_example_receipt1.nc4"
- "Data/sonde_obs_example_receipt2.nc4"
- "Data/sonde_obs_example_receipt3.nc4"
obsdataout:
engine:
type: H5File
obsfile: "FilteredData/sonde_obs_example.nc4"
Here is an example enabling the optional receipt time filter. The variable “MetaData/r2d2ReceiptTime” contains the receipt times for each location, and the accept window is set to the initial 15 minutes of the time window.
---
time window:
begin: "2024-01-10T00:00:00Z"
end: "2024-01-10T06:00:00Z"
obs space:
name: "Single File Input"
simulated variables: ['airTemperature']
obsdatain:
engine:
type: H5File
obsfile: "Data/sonde_obs_example.nc4"
obsdataout:
engine:
type: H5File
obsfile: "FilteredData/sonde_obs_example.nc4"
receipt time filter:
accept window:
begin: "2024-01-10T00:00:00Z"
end: "2024-01-10T00:15:00Z"
variable name: "MetaData/r2d2ReceiptTime"
Here is the above example repeated, except with a receipt time generator specified.
---
time window:
begin: "2024-01-10T00:00:00Z"
end: "2024-01-10T06:00:00Z"
obs space:
name: "Single File Input"
simulated variables: ['airTemperature']
obsdatain:
engine:
type: H5File
obsfile: "Data/sonde_obs_example.nc4"
obsdataout:
engine:
type: H5File
obsfile: "FilteredData/sonde_obs_example.nc4"
receipt time filter:
accept window:
begin: "2024-01-10T00:00:00Z"
end: "2024-01-10T00:15:00Z"
variable name: "MetaData/r2d2ReceiptTime"
generate receipt times:
delay min: 300
delay max: 900
In this example, receipt times are generated and stored into the MetaData/r2d2ReceiptTime variable.
The receipt times are delays lying within the range of 300 to 900 seconds, and the generator algorithm is applying a modulo 600 (delay range) operation on each of the observation time stamp values to help spread out the distribution of delay values.