Objects and Layouts¶
This section describes how all of the fundamental IODA components interact and form a coherent structure. We first briefly describe the ObsGroup and ObsSpace structures, since these are throughout IODA, IODA-converter, and UFO development. Then, we discuss select concepts in greater detail.
ObsGroups & ObsSpaces¶
ObsGroups and ObsSpaces are the main in-memory and on-disk storage structures that are used to organize observation data. An ObsGroup is used to store data from a single data source, such as an instrument. An ObsSpace is a specialization of an ObsGroup that adds in a few user-convenience functions. It will merge with the ObsGroup in a future version of IODA.

Figure 3 — A top-level view of an ObsGroup.
The root group contains one level of child groups and several dimension scales. In the above figure, the child groups are denoted by the folder icon (HofX, MetaData, ObsError, ObsValue, PreQC). The dimension scales are “Channel” and “Location”. Dimension scales should always be located at the root level of an ObsGroup. The root group also has several global attributes that help describe the data.
Global attributes¶
The root group has several global attributes that can help describe the data. For the full list of standardized global attributes, consult the “Global attributes” section of the conventions document. Additional attributes are also possible, but they are optional and are outside the scope of this standards document.
Global attributes may be indexed by R2D2. R2D2-specific attributes are prefixed with “r2d2”. Common attributes are summarized in this table:
Table 2 — Common global attributes. For the full list, see convention tables.
Name |
Required |
Data type |
Description |
Examples |
|---|---|---|---|---|
description |
No |
A description of this data. |
This data set describes snow depth measurements in the Tri-Cities area of northeast Tennessee. |
|
geospatialLatLonExtent |
No |
Variable-length string |
A single-dimensioned array of 4 values. Lat min, lat max, lon min, lon max. |
Use the WTK specification at https://docs.opengeospatial.org/is/18-010r7/18-010r7.html#33 |
keywords |
No |
1-D array of Variable-length strings |
A one-dimentional array of keywords. Keywords may be more than one word. |
[snow depth, tennessee] |
name |
Yes |
Variable-length string |
A name for this data. |
Snow Depth Measurements in Tennessee |
platforms |
No |
1-D array of Variable-length strings |
The platforms that supports the sensors. This attribute should be a string from the “Platform Identifiers” table. |
GOES-16 |
providerFullName |
No |
Variable-length string |
The full, legal name of r2d2Provider. |
National Aeronautics and Space Administration |
r2d2ObsType |
Yes |
Variable-length string |
Lowercase unique identifier for humans. |
raob, atms_n20, abi_g16_bt, metar, synop. |
r2d2SubObsType |
No |
Variable-length string |
Lowercase unique identifier for humans. |
|
r2d2Provider |
Yes |
Variable-length string |
Lowercase provider / publisher of this observation. |
noaa, ucar, nasa, planetiq |
r2d2ProcessingCenter |
No |
Lowercase unique identifier for humans identifying the distributor who has done processing on native data. |
nesdis, nco |
|
r2d2Type |
Yes |
Variable-length string |
Always “obs” for observation data. |
obs |
r2d2WindowStart |
Yes |
Variable-length string |
The beginning of the time window in ISO 8601 format. |
2020-12-16T03:00:00Z |
r2d2WindowLength |
Yes |
Variable-length string |
The length of the time window in ISO 8601 format. |
PT6H, P1D |
sensors |
No |
1-D array of Variable-length strings |
The instruments. This attribute should be a string from the “Instrument Identifiers” table. |
ABI |
uri |
No |
Variable-length string |
A URI pointer to the source of this data. May be a DOI. |
Global attributes added by R2D2 upon ingest¶
Name |
Required by R2D2 |
Data type |
Description |
Examples |
|---|---|---|---|---|
r2d2Database |
Yes |
Variable-length string |
The common name of the R2D2 database containing this data. |
|
r2d2DatabaseLocation |
Yes |
Variable-length string |
The full path to the R2D2 database on disk containing this data or the AWS S3 bucket name |
/work/noaa/da/jedipara/R2D2_SHARED_EWOK2 OR archive.jcsda |
r2d2Id |
Yes |
Variable-length string |
The ID assigned by R2D2 for this data. |
Unique ID assigned by database technology or algorithm to be selected |
r2d2IngestTime |
Yes |
Variable-length string |
The date and time of R2D2 ingest for this data in ISO 8601 |
2022-02-18T07:31:15Z |
r2d2Platform |
Yes |
Variable-length string |
The R2D2 site hosting this data |
Group-based data organization¶
In a Data Assimilation system like JEDI, it is expected that you can use a quantity in many different contexts. For example, you might ingest radiance observations from an instrument. You might also want to run a forward operator, like CRTM or RTTOV, to simulate radiances from the model state. Furthermore, you might also want to perform Quality Control (QC) procedures on your radiance data to adjust initial estimates of Observation Errors (ObsError) or to flag certain data and entirely remove it from your assimilation run. All of these cases highlight the need to organize your data by context.
Throughout IODA, we combine context with variable names by grouping variables according to context. In other words, we create a series of Groups (e.g. ObsValue, MetaData, HofX, ObsError, etc.) and organize our data into these groups. See the below figure for an example of this organizational structure. The “brightnessTemperature” variable occurs in several groups, depending on whether it represents an observed quantity, the product of a forward operator, the estimated initial error of an observation, or if there is upstream QC information about an observation.
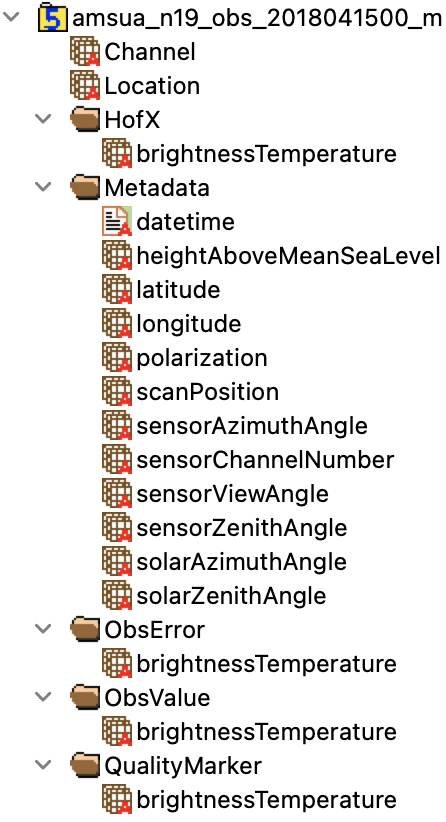
Figure 4 — Expanded view of an ObsGroup
The ObsGroup will always have multiple child groups. At a minimum, users can expect that the “MetaData” and “ObsValue” group will always be present. These child groups will never have their own attributes, the child groups will not contain further groups, and the child groups will not contain dimension scales. Common group names and meanings are detailed below. This is not an exhaustive list, but it covers 99% of the expected cases.
Table 3 — Common group names and meanings
Group Name |
Meaning |
|---|---|
ObsValue |
For when a specific variable is a direct observed/reported measurement, such as satellite radiance or surface weather observations of airTemperature and dewpointTemperature. |
DerivedObsValue |
For when a variable is derived from the direct/measured quantity such as satellite brightnessTemperature or relativeHumidity. |
EffectiveObsValue |
This group name is UFO’s computed effective obsValue after bias correction or adjustment (for example adjusting observation value with respect to model height). |
Metadata |
Use this group name for ancillary data that provides added description to an ObsValue in general. Simple examples are stationElevation and airTemperature to provide the added information needed for the altitude for which a surface temperature observation was made. Similarly, the airPressure, altitude, and eastwardWind for radiosonde or satellite atmospheric motion vector winds. |
HofX |
This is the end product of the forward operator, known in DA as H(x) or HofX. |
ObsError |
This group name denotes Observation Errors that arrive from upstream data sources. The values are usually considered to be the standard deviation of observation errors. |
EffectiveError |
This group name is UFO’s computed effective ObsError value after any number of QC steps that may “inflate” or alter the ObsError. In JEDI, this final value given to the DA means that ObsValues with large relative EffectiveError have less impact than relatively small EffectiveError values. |
QualityMarker (formerly PreQC) |
This group name is for legacy systems in which quality markers might be assigned by various data pre-processing software before creating the IODA files/streams for use in UFO. |
EffectiveQC |
This group name is UFO’s final QC value given by the QCflags.h enumeration of values associated with various QC rejection or other steps. Examples include Bounds Check, Domain Check, Background Check, etc. |
Variable names¶
Each group is expected to contain one or more variables. The variables in a group should correspond to an entry in the Conventions Tables.
This spreadsheet is organized into several related tables, which are accessible using the tabs at the bottom of the document. When manipulating variables, the relevant tabs include: “Variables”, “Dimensions”, “Data Storage Types”, and “Common Variable Attributes.”
The list of variables in the Conventions Table was created mostly from similar variable names used in WMO BUFR formatted data in version number 36 of the WMO element tables. Not all variables currently in use (or planned) in IODA/UFO/JEDI can be found in these tables, so new names have been inserted where needed. For the most part, the tables show variable names with an adjective preceding the noun, e.g., dewpointTemperature. This is not necessarily ideal for searching tables by categories of names, which might be facilitated by having noun first, then adjective (temperatureDewpoint, temperatureVirtual, temperatureWetbulb for example). These tables use “camelCase” rather than “snake_case”. Wherever possible, variables that are part of categories are reasonably close to each other in the list.
It is our preference to use reasonably descriptive variable names yet be as brief as possible. A very good example would be “total column integrated water vapor.” This is nothing more than precipitable water by the classic definition.
At this time, we are keeping close control over the addition of new variable names because we wish to avoid a proliferation of duplicative names. This tight control is temporary and we intend to formalize a process typical of JEDI development with GitHub pull requests for adding new names and documentation. It will be imperative to include some persons with previous experience with the existing naming conventions so that experienced users may guide the person seeking a new name to an already existing name that could suffice for the job.
It is advisable to search for a major portion of a word associated with a variable before trying to come up with a newly named variable.
Variable properties and attributes¶
Detailed information about each variable is specified in the conventions table. This includes the variable’s storage type, units, suggested dimensions, and a human-readable description. All variables used in IODA should be documented in the table. If a variable is not documented, please contact the authors to have it added.
Storage type and missing values¶
The variable’s “data storage type” is the type used internally for storing the variable’s data. IODA is flexible regarding the type that an end user is using to access the data. That is, a user can use a double-precision integer to read data stored using a single-precision integer. Or, a user can read a small unsigned integer as a large signed integer. If possible, users should use the data types specified in the table for data access. This avoids accidental truncation or mangling of data. It also avoids performance issues inherent with type conversions.
The “Data Storage Types” table lists all of the data types supported in IODA objects. This table includes minimum and maximum values for each type.
Whenever accessing a variable, users should query IODA to determine the value used to denote missing data. Missing data is denoted by setting a datum to the variable’s fill value. To query the fill value of a variable, you can either 1) read the contents of its “_FillValue” attribute, or 2) call the variable’s getFillValue() function.
Note: Strictly speaking, a fill value is a special value that denotes a missing or unwritten data range inside of a file. Assume that you create a variable and never write to it. Upon reading the variable you would not encounter an error. Instead, IODA would return an array of elements filled with the fill value. Since a “missing value” falls within the definition of a “fill value”, we use these terms interchangeably.
IODA’s missing value and fill value indicators are somewhat inconsistent across data sources. OOPS defines default missing values via the oops::missingValue() functions. These defaults are defined in the table below. They typically match missing values defined in IODA variables, but not always.
Table 4 — Missing value markers used elsewhere in the JEDI project
C++ type |
JEDI/OOPS missing value definition |
Value |
|---|---|---|
float |
|
|
double |
|
|
int16_t |
|
|
int32_t |
|
|
int64_t |
|
|
DateTime |
|
|
string |
|
Other data types (e.g. unsigned integers) are infrequently found elsewhere in JEDI and have no explicit missing value. If a value is unlisted in the table, then the default fill value is zero. Consistent and comprehensive handling of missing data is a long-term goal of the project.
The fill value should not be used in mathematical calculations. It has no physical meaning. Missing values should be tested and flagged appropriately within the user code. Fill values and missing values in IODA are never NaNs. They are also never ±∞ nor any other machine architecture-dependent value. Every variable should define sensible fill values. This fill value should not reside within the expected valid range of the variable.
It is important to note that the fill value is set based on the storage type, and not the data type that you are using to read or write data. For example, if you read data stored using type int16_t (a 16-bit signed integer) as an int32_t (a 32-bit signed integer), then the fill value will be -32767 instead of -2147483647. Additionally, the fill value is customizable upon variable creation and may differ from the default. It is the responsibility of the caller to ensure that the appropriate fill value is understood.
Attributes and Units¶
Each variable in an ObsGroup is expected to have one or more attributes that help describe the data within the variable. Readers should consult the “Common Variable Attributes” sheet in the conventions tables for the complete list.
Variables should follow SI units wherever possible unless a common convention in the field does otherwise. Appropriate units for each variable are specified in the Conventions Table. As IODA data should be self-documenting, all variables in a valid IODA file should explicitly specify their units. Units should be specified as a UDUNITS-parsable string attribute that is attached to each variable. Units and Symbols Found in the UDUNITS2 Database:https://ncics.org/portfolio/other-resources/udunits2/.
For variables such as mass mixing ratio (of water species), the units should not be unitless, but, rather should express the units hidden within the ratio (such as “kg kg-1”). Variables that are unitless but have physical meaning or could be used in math formulas (e.g. aerosol optical depth) should have units set to ‘1’. Variables that cannot be used in mathematical formulas (e.g. categorical variables) should specify “unitless” as their units.
Using dimensions properly¶
Variables may have any number of dimensions (think of them as N-dimensional arrays), but each dimension must have an attached dimension scale that is used to assign “meaning” to each dimension axis.
Suggested dimensions are listed in the conventions tables. For example, for an instrument that records brightness temperatures, there should be a “brightnessTemperature” variable that has dimensions of Location x Channel. The brightnessTemperature variable’s lengths along each axis should match the lengths of each attached dimension scale (see Dimension Scales). If an ObsGroup has 500 observation locations and 22 instrument channels, then the brightnessTemperature variable should be a 500x22 array.
Variables are not required to exactly adhere to the suggested dimensions in the conventions tables. These dimensions are recommended and are usually the best choice. However, there are certain situations where data are degenerate or redundant along one dimension. For example, for most radiometers scan angle is a function only of scan position. The dimensions of “scanAngle” should therefore be Location. However, for GMI scan angle varies with instrument channel, so “scanAngle” should have dimensions of Location x Channel. Similar situations may occur elsewhere and will be noted in the conventions document. It is the responsibility of the caller to properly query a variable’s dimension scales when ambiguity is possible.
Other Data Organizational Structures¶
Bias-related data¶
Bias coefficients used in variational bias correction for radiances are stored in IODA files (one file per one instrument and satellite). Unlike with ObsGroups, bias coefficients have no group structure. Everything is located at the root group level.

Figure 5 — Example bias coefficients file for Suomi-NPP’s ATMS instrument
This is the format:
Dimensions:
nchannels(number of radiance channels)npredictors(number of bias correction predictors)
Variables:
channels(nchannels): integer, list of channels numberspredictors(npredictors): string, list of predictor namesbias_coefficients(npredictors,nchannels): float, bias coefficients for each channel and predictorbias_coeff_errors(npredictors,nchannels): float, bias coefficient error variances for each channel and predictornumber_obs_assimilated(nchannels): float, number of observations assimilated at the previous analysis step for each channel (used in setting up bias coefficient error covariances).
For static bias correction coefficients are automatically set to 1.0 and do not need to be defined in an external file. However, predictor values need to be provided via either a CSV or a NetCDF file.
The files have no set dimensions or variables but should adhere to the following structure (note that additional examples are available in the JEDI docs):
CSV files: An input CSV file should have the following structure:
First line: comma-separated column names in ioda-v2 style (Group/var)
Second line: comma-separated column data types (datetime, float, int or string)
Further lines: comma-separated data entries
The number of entries in each line should be the same. The column order does not matter. One of the columns should belong to the ObsBias group and contain the bias corrections to use in specific circumstances. Its data type should be either float or int. The values from the other columns (sometimes called coordinates below) are compared against ObsSpace variables with the same names to determine the row or rows from which the bias correction is extracted at each location.
NetCDF files:
Bias corrections should be stored in an array placed in the ObsBias group
Coordinate variables should be placed in appropriate groups, e.g. MetaData. Because of the limitations of the NetCDF file format, these variables can only be used as auxiliary coordinates of the payload variable