Generic QC Filters¶
This section describes how to configure each of the existing QC filters in UFO. All filters can also use the “where” statement to act only on observations meeting certain conditions. By default, each filter acts on all the variables marked as simulated variables in the ObsSpace. The filter variables keyword can be used to limit the action of the filter to a subset of these variables or to specific channels, as shown in the examples from the Bounds Check Filter section below.
Bounds Check Filter¶
This filter rejects observations whose values (@ObsValue in the ioda files) lie outside specified limits:
- filter: Bounds Check
filter variables:
- name: brightness_temperature
channels: 4-6
minvalue: 240.0
maxvalue: 300.0
In the above example the filter checks if brightness temperature for channels 4, 5 and 6 is outside of the [240, 300] range. Suppose we have the following observation data with 3 locations and 4 channels:
channel 3: [100, 250, 450]
channel 4: [250, 260, 270]
channel 5: [200, 250, 270]
channel 6: [340, 200, 250]
In this example, all observations from channel 3 will pass QC because the filter isn’t configured to act on this channel. All observations for channel 4 will pass QC because they are within [minvalue, maxvalue]. 1st observation in channel 5, and first and second observations in channel 6 will be rejected.
- filter: Bounds Check
filter variables:
- name: air_temperature
minvalue: 230
- filter: Bounds Check
filter variables:
- name: eastward_wind
- name: northward_wind
minvalue: -40
maxvalue: 40
In the above example two filters are configured, one testing temperature, and the other testing wind components. The first filter would reject all temperature observations that are below 230. The second, all wind component observations whose magnitude is above 40.
In practice, one would be more likely to want to filter out wind component observations based on the value of the wind speed sqrt(eastward_wind**2 + northward_wind**2). This can be done using the test variables keyword, which rejects observations of a variable if the value of another lies outside specified bounds. The “test variable” does not need to be a simulated variable; in particular, it can be an ObsFunction, i.e. a quantity derived from simulated variables. For example, the following snippet filters out wind component observations if the wind speed is above 40:
- filter: Bounds Check
filter variables:
- name: eastward_wind
- name: northward_wind
test variables:
- name: Velocity@ObsFunction
maxvalue: 40
If there is only one entry in the test variables list, the same criterion is applied to all filter variables. Otherwise the number of test variables needs to match that of filter variables, and each filter variable is filtered according to the values of the corresponding test variable.
Background Check Filter¶
This filter checks for bias corrected distance between observation value and model simulated value (\(y-H(x)\)) and rejects obs where the absolute difference is larger than absolute threshold, or threshold * \({\sigma}_o\), or threshold * \({\sigma}_b\), where \({\sigma}_o\) is observation error and \({\sigma}_b\) is background error. This filter can also adjust observation error through a constant inflation factor when the filter action is set to inflate error. If no action section is included in the yaml, the filter is set to reject the flagged observations.
- filter: Background Check
filter variables:
- name: air_temperature
threshold: 2.0
absolute threshold: 1.0
action:
name: reject
- filter: Background Check
filter variables:
- name: eastward_wind
- name: northward_wind
threshold: 2.0
where:
- variable:
name: latitude@MetaData
minvalue: -60.0
maxvalue: 60.0
action:
name: inflate error
inflation: 2.0
- filter: Background Check
filter variables:
- name: sea_surface_height
threshold wrt background error: true
threshold: 2.0
The first filter would flag temperature observations where \(|y-(H(x)+bias)| > \min (\) absolute_threshold, threshold * \({\sigma}_o)\), and
then the flagged data are rejected due to the filter action being set to reject.
The second filter would flag wind component observations where \(|y-(H(x)+bias)| >\) threshold * \({\sigma}_o\) and latitude of the observation location are within 60 degree. The flagged data will then be inflated with a factor 2.0.
Please see the Filter Actions section for more detail.
The third filter compares the departure against the background error rather than the observation error. It would flag sea surface height observations where \(|y-(H(x)+bias)| >\) threshold * \({\sigma}_b\), and reject the flagged observations as no filter action is specified. If threshold wrt background error is set to true, then threshold must be set and absolute threshold must not.
There is an option for the background check filter to check for distance between observation value and model simulated value without bias correction (\(y-H(x)\)) when the additional parameter bias correction parameter is set to 1.0 and rejects obs where the absolute difference is larger than absolute threshold or threshold * \({\sigma}_o\) when the filter action is set to reject. If no action section is included in the yaml, the filter is set to reject the flagged observations.
- filter: Background Check
filter variables:
- name: brightness_temperature
channels: 1-24
absolute threshold: 3.5
bias correction parameter: 1.0
action:
name: reject
This filter would flag temperature observations where \(|y-H(x)| > \min (\) absolute_threshold, threshold * \({\sigma}_o)\), and then the flagged data are rejected due to filter action is set to reject.
Bayesian Background Check Filter¶
Similar to the standard Background Check filter, which rejects observations based on the difference between observation value and model simulated value (\(y-H(x)\)), the Bayesian Background Check also takes into account the probability that an observation is “bad”, i.e. “in gross error”.
The .yaml file requires the following filter parameters:
prob density bad obs (
PdBad): the value of the prior uniform probability distribution for the observation to be bad (e.g. 0.1/K for a domain 273-283 K for some temperature observation);initial prob gross error (
PGE): the weight given to the uniform (“bad”) probability distribution - while(1-PGE)is the weight given to the “good” distribution (a Gaussian in \([y-H(x)]\), with variance \({\sigma}^2\) given by the sum of background uncertainty and observation uncertainty variances).
The initial PGE divided by the combined probability distribution, gives the conditional probability that the observation is in gross error. This conditional probability value is the after-check PGE, PGEBd. It is saved in the ObsSpace for optional later use in the buddy check.
The .yaml file can also contain optional filter parameters, which override the default values in ufo/utils/ProbabilityOfGrossErrorParameters.h:
PGE threshold (
PGECrit, default 0.1): if the adjusted (after-check) PGE exceeds this value, the observation is rejected;obs minus BG threshold (
SDiffCrit, default 100.0): if the observation-background normalised square-difference \([y-H(x)]^2/{\sigma}^2\) exceeds this value, the observation is rejected;max exponent (
ExpArgMax, default 80.0): maximum allowed value of the exponent in the “good” probability distribution;obs error multiplier (
ObErrMult, default 1.0): weight of observation error in the combined error variance;BG error multiplier (
BkgErrMult, default 1.0): weight of background error in the combined error variance.
- filter: Bayesian Background Check
filter variables:
- name: ice_area_fraction
prob density bad obs: 1.0
initial prob gross error: 0.04
PGE threshold: 0.07
obs minus BG threshold: 100.0
Note that this filter requires the background value (HofX) and background uncertainty. The latter is accessed from the obs diagnostics - as an interim measure, supplied in a separate .nc4 file (see .yaml snippet below), with variable name e.g. ice_area_fraction_background_error (no @ group name) to go with ice_area_fraction.
HofX: HofX
obs diagnostics:
filename: Data/ufo/testinput_tier_1/background_errors_for_bayesianbgcheck_test.nc4
By default, a filter variable is treated as scalar. But for vectors, such as wind, the two components must be specified one after the other in the .yaml, and the first must have the option first_component_of_two set to true.
- filter: Bayesian Background Check
filter variables:
- name: eastward_wind
options:
first_component_of_two: true
- name: northward_wind
Bayesian Background check currently only works for single-level observations, not profiles.
Domain Check Filter¶
This filter retains all observations selected by the “where” statement and rejects all others. Below, the filter is configured to retain only observations
* taken at locations where the sea surface temperature retrieved from the model is between 200 and 300 K (inclusive)
* with valid height metadata (not set to “missing value”)
* taken by stations with IDs 3, 6 or belonging to the range 11-120
* without valid air_pressure metadata.
- filter: Domain Check
where:
- variable:
name: sea_surface_temperature@GeoVaLs
minvalue: 200
maxvalue: 300
- variable:
name: height@MetaData
is_defined:
- variable:
name: station_id@MetaData
is_in: 3, 6, 11-120
- variable:
name: air_pressure@MetaData
is_not_defined:
BlackList Filter¶
This filter behaves like the exact opposite of Domain Check: it rejects all observations selected by the “where” statement statement. The status of all others remains the same. Below, the filter is configured to reject observations taken by stations with IDs 1, 7 or belonging to the range 100-199:
- filter: BlackList
where:
- variable:
name: station_id@MetaData
is_in: 1, 7, 100-199
RejectList Filter¶
This is an alternative name for the BlackList filter.
AcceptList Filter¶
This filter sets the QC flag to pass for all observations selected by the “where” statement that have previously been rejected for any reason other than missing data, a pre-processing flag indicating rejection, or failure of the ObsOperator. This is mostly useful in QC procedures where all observations are initially rejected and then those fulfilling certain criteria are accepted, overriding the rejection.
Below, the filter is configured to accept only observations taken by stations with IDs 1, 7 or belonging to the range 100-199 (inclusive):
- filter: RejectList # initially reject all observations
- filter: AcceptList # accept back selected observations
where:
- variable:
name: station_id@MetaData
is_in: 1, 7, 100-199
Perform Action Filter¶
This filter performs the action specified in the action parameter on observations selected by the “where” statement.
Example 1¶
Here the filter is configured to inflate errors of all observations from the Southern hemisphere by a factor of two:
- filter: Perform Action
action:
name: inflate error
inflation: 2.0
where:
- variable: latitude
maxvalue: 0
Note
Technically, the same result could be obtained by replacing Perform Action in the listing
above by RejectList. However, having a RejectList filter that does not actually
reject any observations can be confusing.
Example 2¶
The filter configured in this way behaves like RejectList:
- filter: Perform Action
action:
name: reject
Example 3¶
The filter configured in this way behaves like AcceptList:
- filter: Perform Action
action:
name: accept
Thinning Filter¶
This filter rejects a specified fraction of observations, selected at random. It supports the following YAML parameters:
amount: the fraction of observations to reject (a number between 0 and 1).random seed(optional): an integer used to initialize a random number generator if it has not been initialized yet. If not set, the seed is derived from the calendar time.
Note: because of how this filter is implemented, the fraction of rejected observations may not be exactly equal to amount, especially if the total number of observations is small.
Example:
- filter: Thinning
amount: 0.75
random seed: 125
Gaussian Thinning Filter¶
This filter thins observations by preserving only one observation in each cell of a grid. Cell assignment can be based on an arbitrary combination of:
horizontal position
vertical position (in terms of height or pressure)
time
category (arbitrary integer associated with each observation).
Selection of the observation to preserve in each cell is based on
its position in the cell
optionally, its priority.
The following YAML parameters are supported:
Horizontal grid:
horizontal_mesh: Approximate width (in km) of zonal bands into which the Earth’s surface is split. Thinning in the horizontal direction is disabled if this parameter is negative. Default: approx. 111 km (= 1 deg of latitude).use_reduced_horizontal_grid: True to use a reduced grid, with high-latitude zonal bands split into fewer cells than low-latitude bands to keep cell size nearly uniform. False to use a regular grid, with the same number of cells at all latitudes. Default:true.round_horizontal_bin_count_to_nearest: True to set the number of zonal bands so that the band width is as close as possible tohorizontal_mesh, and the number of cells (“bins”) in each zonal band so that the cell width in the zonal direction is as close as possible to that in the meridional direction. False to set the number of zonal bands so that the band width is as small as possible, but no smaller thanhorizontal_mesh, and the cell width in the zonal direction is as small as possible, but no smaller than in the meridional direction.Defaults to
falseunless theops_compatibility_modeoption is enabled, in which case it’s set totrue.
Vertical grid:
vertical_mesh: Cell size in the vertical direction. Thinning in the vertical direction is disabled if this parameter is not specified or negative.vertical_min: Lower bound of the vertical coordinate interval split into cells of sizevertical_mesh. Default: 100 (Pa).vertical_max: Upper bound of the vertical coordinate interval split into cells of sizevertical_mesh. This parameter is rounded upwards to the nearest multiple ofvertical_meshstarting fromvertical_min. Default: 110,000 (Pa).vertical_coordinate: Name of the observation vertical coordinate. Default:air_pressure.
Temporal grid:
time_mesh: Cell size in the temporal direction. Temporal thinning is disabled if this this parameter is not specified or set to 0.time_min: Lower bound of the time interval split into cells of sizetime_mesh. Temporal thinning is disabled if this parameter is not specified.time_max: Upper bound of the time interval split into cells of sizetime_mesh. This parameter is rounded upwards to the nearest multiple oftime_meshstarting fromtime_min. Temporal thinning is disabled if this parameter is not specified.
Observation categories:
category_variable: Variable storing integer-valued IDs associated with observations. Observations belonging to different categories are thinned separately.
Selection of observations to retain:
priority_variable: Variable storing observation priorities. Among all observations in a cell, only those with the highest priority are considered as candidates for retaining. If not specified, all observations are assumed to have equal priority.distance_norm: Determines which of the highest-priority observations lying in a cell is retained. Allowed values:geodesic: retain the observation closest to the cell center in the horizontal direction (the vertical coordinate and time are ignored when selecting the observation to retain)maximum: retain the observation lying furthest from the cell’s bounding box in the system of coordinates in which the cell is a unit cube (all dimensions along which thinning is enabled are taken into account).
Defaults to
geodesicunless theops_compatibility_modeoption is enabled, in which case it’s set tomaximum.ops_compatibility_mode: Set this option totrueto make the filter produce identical results as theOps_Thinningsubroutine from the Met Office OPS system when both are run serially (on a single process).This modifies the filter behavior in the following ways:
The
round_horizontal_bin_count_to_nearestoption is set totrue.The
distance_normoption is set tomaximum.Bin indices are calculated by rounding values away from rather towards zero. This can alter the bin indices assigned to observations lying at bin boundaries.
The bin lattice is assumed to cover the whole real axis (for times and pressures) or the [-360, 720] degrees interval (for longitudes) rather than just the intervals [
time_min,time_max], [pressure_min,pressure_max] and [0, 360] degrees, respectively. This may cause observations lying at the boundaries of the latter intervals to be put in bins of their own, which is normally undesirable.A different (non-stable) sorting algorithm is used to order observations before inspection. This can alter the set of retained observations if some bins contain multiple equally good observations (with the same priority and distance to the cell center measured with the selected norm). If this happens for a significant fraction of bins, it may be a sign the criteria used to rank observations (the priority and the distance norm) are not specific enough.
Example 1 (thinning by the horizontal position only):
- filter: Gaussian Thinning
horizontal_mesh: 1111.949266 #km = 10 deg at equator
Example 2 (thinning observations from multiple categories and with non-equal priorities by their horizontal position, pressure and time):
- filter: Gaussian Thinning
distance_norm: maximum
horizontal_mesh: 5000
vertical_mesh: 10000
time_mesh: PT01H
time_min: 2018-04-14T21:00:00Z
time_max: 2018-04-15T03:00:00Z
category_variable:
name: instrument_id@MetaData
priority_variable:
name: priority@MetaData
Temporal Thinning Filter¶
This filter thins observations so that the retained ones are sufficiently separated in time. It supports the following YAML parameters:
min_spacing: Minimum spacing between two successive retained observations. Default:PT1H.seed_time: If not set, the thinning filter will consider observations as candidates for retaining in chronological order.If set, the filter will start from the observation taken as close as possible to
seed_time, then consider all successive observations in chronological order, and finally all preceding observations in reverse chronological order.category_variable: Variable storing integer-valued IDs associated with observations. Observations belonging to different categories are thinned separately. If not specified, all observations are thinned together.priority_variable: Variable storing integer-valued observation priorities. If not specified, all observations are assumed to have equal priority.tolerance: Only relevant ifpriority_variableis set.If set to a nonzero duration, then whenever an observation O lying at least
min_spacingfrom the previous retained observation O’ is found, the filter will inspect all observations lying no more thantolerancefurther from O’ and retain the one with the highest priority. In case of ties, observations closer to O’ are preferred.
Example 1 (selecting at most one observation taken by each station per 1.5 h, starting from the observation closest to seed time):
- filter: Temporal Thinning
min_spacing: PT01H30M
seed_time: 2018-04-15T00:00:00Z
category_variable:
name: call_sign@MetaData
Example 2 (selecting at most one observation taken by each station per 1 h, starting from the earliest observation, and allowing the filter to retain an observation taken up to 20 min after the first qualifying observation if its quality score is higher):
- filter: Temporal Thinning
min_spacing: PT01H
tolerance: PT20M
category_variable:
name: call_sign@MetaData
priority_variable:
name: score@MetaData
Poisson Disk Thinning Filter¶
This filter thins observations by iterating over them in random order and retaining each observation lying outside the exclusion volumes (ellipsoids or cylinders) surrounding observations that have already been retained.
The following YAML parameters are supported:
Exclusion volume:
min_horizontal_spacing: Size of the exclusion volume in the horizontal direction (in km).If the priority_variable parameter is set, this parameter may be a map assigning an exclusion volume size to each observation priority, or a floating-point constant. If the priority_variable parameter is not set (and hence all observations have the same priority), this parameter must be a floating-point constant. Exclusion volumes of lower-priority observations must be at least as large as those of higher-priority ones. If this parameter is not set, horizontal position is ignored during thinning.
Note: Owing to a bug in the eckit YAML parser, maps need to be written in the JSON style, with keys quoted. Example:
min_horizontal_spacing: {"1": 123, "2": 321}
This will not work:
min_horizontal_spacing: {1: 123, 2: 321}
and neither will this:
min_horizontal_spacing: 1: 123 2: 321
nor this:
min_horizontal_spacing: "1": 123 "2": 321
min_vertical_spacing: Size of the exclusion volume in the vertical direction (in Pa).Like
min_horizontal_spacing, this parameter can be either a constant or a map. If not set, vertical position is ignored during thinning.min_time_spacing: Size of the exclusion volume in the temporal direction.Like
min_horizontal_spacing, this parameter can be either a constant or a map. If not set, observation time is ignored during thinning.exclusion_volume_shape: Shape of the exclusion volume surrounding each observation.Allowed values:
cylinder: the exclusion volume of an observation taken at latitude lat, longitude lon, pressure p and time t is the set of all locations (lat’, lon’, p’, t’) for which all of the following conditions are met:the geodesic distance between (lat, lon) and (lat’, lon’) is smaller than min_horizontal_spacing
|p - p’| < min_vertical_spacing
|t - t’| < min_time_spacing.
ellipsoid: the exclusion volume of an observation taken at latitude lat, longitude lon, pressure p and time t is the set of all locations (lat’, lon’, p’, t’) for which the following condition is met:geodesic_distance((lat, lon), (lat’, lon’))^2 / min_horizontal_spacing^2 + (p - p’)^2 / min_vertical_spacing^2 + (t - t’)^2 / min_time_spacing^2 < 1.
Default:
cylinder.
Observation categories:
category_variable: Variable storing integer-valued IDs associated with observations. Observations belonging to different categories are thinned separately. If not set, all observations are thinned together.
Selection of observations to retain:
priority_variable: Variable storing observation priorities. An observation will not be retained if it lies within the exclusion volume of an observation with a higher priority.As noted in the documentation of
min_horizontal_spacing, the exclusion volume size must be a (weakly) monotonically decreasing function of observation priority, i.e. the exclusion volumes of all observations with the same priority must have the same size, and the exclusion volumes of lower-priority observations must be at least as large as those of higher-priority ones.If this parameter is not set, all observations are assumed to have equal priority.
shuffle: If true, observations will be randomly shuffled before being inspected as candidates for retaining. Default: true.Note: It is recommended to leave shuffling enabled in production code, since the performance of the spatial point index (kd-tree) used in the filter’s implementation may be degraded if observation locations are ordered largely monotonically (and random shuffling essentially prevents that from happening).
random_seed: Seed with which to initialize the random number generator used to shuffle the observations ifshuffleis set to true.If omitted, a seed will be generated based on the current (calendar) time.
Example 1¶
With the following parameters, observations are thinned by horizontal position only. The exclusion volume size depends on the observation priority. Each scan is thinned separately.
- filter: Poisson Disk Thinning
min_horizontal_spacing: {"0": 600, "1": 200} # priority -> km
category_variable:
name: scan_index@MetaData
priority_variable:
name: priority@MetaData
random_seed: 12345
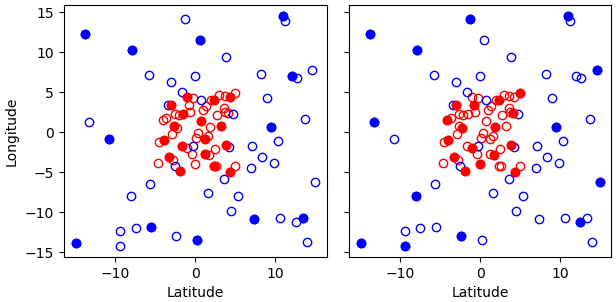
Fig. 15 Results of running the Poisson-disk thinning filter on sample data with the above parameters and two different random seeds. All observations have the same scan index. Observations with priorities 1 and 0 are marked with red and blue circles, respectively. Circles denoting retained observations are filled; those denoting rejected observations are empty. Note how blue (low-priority) observations are retained only in regions without red (high-priority) observations.¶
Example 2¶
With the following parameters, observations are thinned by the horizontal position, vertical position and time. The exclusion volumes are ellipsoidal. Shuffling is disabled.
- filter: Poisson Disk Thinning
min_horizontal_spacing: 1000 # km
min_vertical_spacing: 10000 # Pa
min_time_spacing: PT1H
exclusion_volume_shape: ellipsoid
shuffle: false
Stuck Check Filter¶
This filter thins observations by iterating over them by station and flagging each observation that
is part of a “streak” of sequential observations. The first condition for a “streak” is that the
observational values are the same over a certain count of sequential observations. The second
condition is either (a) that this set of observations is longer than a user-defined duration or (b)
that it covers the full trajectory of a station.
The observational values which are used for evaluation of whether a “streak” exists are the
filter variables. If multiple filter variables are present, then each variable is
considered independently. In other words the filter flags observations based on each variable,
independent to the other variables.
the original full track for each filter variable. Any observations that form streaks in at least one
variable will be flagged.
The following YAML parameters are supported:
filter variables: the variables to use to classify observations as “stuck”. This required parameter must be entered as a string vector.number stuck tolerance: the maximum number of observations in a row with the same observational value before its classification as a potential streak is made. This required parameter must be entered as a non-negative integer.time stuck tolerance: the maximum time duration before a potential streak is rejected This required parameter must be entered in ISO 8601 duration format. Ifnumber stuck toleranceis exceeded and all of the station’s observations are part of the same streak,time stuck toleranceis ignored and all of the observations are rejected regardless of the duration.
Example 1¶
With the following parameters, a “streak” of observations is defined as sequential observations with identical air temperature measured values. All observations in the streak will be flagged if the streak (a) consists of more than 2 observations and (b) lasts longer than 2 hours or consists of the full set of observations from the station.
- filter: Stuck Check:
filter variables: [air_temperature]
number stuck tolerance: 2
time stuck tolerance: PT2H
Example 2¶
With the following parameters, 2 types of streaks will be identified independently and the observations will be flagged accordingly if either of the following observed values are classified as “stuck”: air temperature and air pressure.
- filter: Stuck Check:
filter variables: [air_temperature, air_pressure]
number stuck tolerance: 2
time stuck tolerance: PT2H
Say we have 5 observations each taken an hour apart. Let the air temperature values equal: 274, 274 274, 275, 275; and the air pressure values equal 4, 4, 5, 5, 5. In this case, all of the observations would be rejected.
Difference Check Filter¶
This filter will compare the difference between a reference variable and a second variable and assign a QC flag if the difference is outside of a prescribed range.
For example:
- filter: Difference Check
reference: brightness_temperature_8@ObsValue
value: brightness_temperature_9@ObsValue
minvalue: 0
The above YAML is checking the difference between brightness_temperature_9@ObsValue and brightness_temperature_8@ObsValue and rejecting negative values.
In psuedo-code form:
if (brightness_temperature_9@ObsValue - brightness_temperature_8@ObsValue < minvalue) reject_obs()
- The options for YAML include:
minvalue: the minimum value the differencevalue - referencecan be. Set this to 0, for example, and all negative differences will be rejected.maxvalue: the maximum value the differencevalue - referencecan be. Set this to 0, for example, and all positive differences will be rejected.threshold: the absolute value the differencevalue - referencecan be (sign independent). Set this to 10, for example, and all differences outside of the range from -10 to 10 will be rejected.
Note that threshold supersedes minvalue and maxvalue in the filter.
Derivative Check Filter¶
This filter will compute a local derivative over each observation record and assign a QC flag if the derivative is outside of a prescribed range.
- By default, this filter will compute the local derivative at each point in a record.
For the first location (1) in a record:
dy/dx = (y(2)-y(1))/(x(2)-x(1))For the last location (n) in a record:
dy/dx = (y(n)-y(n-1))/(x(n)-x(n-1))For all other locations (i):
dy/dx = (y(i+1)-y(i-1))/(x(i+1)-x(i-1))
Alternatively if one wishes to use a specific range/slope for the entire observation record, i1 and i2 can be defined in the YAML.
For this case, For all locations in the record:
dy/dx = (y(i2)-y(i1))/(x(i2)-x(i1))
Note that this filter really only works/makes sense for observations that have been sorted by the independent variable and grouped by some other field.
An example:
- filter: Derivative Check
independent: datetime
dependent: air_pressure
minvalue: -50
maxvalue: 0
passedBenchmark: 238 # number of passed obs
The above YAML is checking the derivative of air_pressure with respect to datetime for a radiosonde profile and rejecting observations where the derivative is positive or less than -50 Pa/sec.
- The options for YAML include:
independent: the name of the independent variable (dx)dependent: the name of the dependent variable (dy)minvalue: the minimum value the derivative can be without the observations being rejectedmaxvalue: the maximum value the derivative can be without the observations being rejectedi1: the index of the first observation location in the record to usei2: the index of the last observation location in the record to use
- A special case exists for when the independent variable is ‘distance’, meaning the dx is computed from the difference of latitude/longitude pairs converted to distance.
Additionally, when the independent variable is ‘datetime’ and the dependent variable is set to ‘distance’, the derivative filter becomes a speed filter, removing moving observations when the horizontal speed is outside of some range.
Track Check Filter¶
This filter checks tracks of mobile weather stations, rejecting observations inconsistent with the rest of the track.
Each track is checked separately. The algorithm performs a series of sweeps over the observations from each track. For each observation, multiple estimates of the instantaneous speed and (optionally) ascent/descent rate are obtained by comparing the reported position with the positions reported during a number a nearby (earlier and later) observations that haven’t been rejected in previous sweeps. An observation is rejected if a certain fraction of these estimates lie outside the valid range. Sweeps continue until one of them fails to reject any observations, i.e. the set of retained observations is self-consistent.
Note that this filter was originally written with aircraft observations in mind. However, it can potentially be useful also for other observation types.
The following YAML parameters are supported:
temporal_resolution: Assumed temporal resolution of the observations, i.e. absolute accuracy of the reported observation times. Default: PT1M.spatial_resolution: Assumed spatial resolution of the observations (in km), i.e. absolute accuracy of the reported positions.Instantaneous speeds are estimated conservatively with the formula
speed_estimate = (reported_distance - spatial_resolution) / (reported_time + temporal_resolution).
The default spatial resolution is 1 km.
num_distinct_buddies_per_direction,distinct_buddy_resolution_multiplier: Control the size of the set of observations against which each observation is compared.Let O_i (i = 1, …, N) be the observations from a particular track ordered chronologically. Each observation O_i is compared against m observations immediately preceding it and n observations immediately following it. The number m is chosen so that {O_{i-m}, …, O_{i-1}} is the shortest sequence of observations preceding O_i that contains
num_distinct_buddies_per_directionobservations distinct from O_i that have not yet been rejected. Two observations taken at times t and t’ and locations x and x’ are deemed to be distinct if the following conditions are met:|t’ - t| >
distinct_buddy_resolution_multiplier*temporal_resolution|x’ - x| >
distinct_buddy_resolution_multiplier*spatial_resolution
Similarly, the number n is chosen so that {O_{i+1}, …, O_{i+n)} is the shortest sequence of observations following O_i that contains
num_distinct_buddies_per_directionobservations distinct from O_i that have not yet been rejected.Both parameters default to 3.
max_climb_rate: Maximum allowed rate of ascent and descent (in Pa/s). If not specified, climb rate checks are disabled.max_speed_interpolation_points: Encoding of the function mapping air pressure (in Pa) to the maximum speed (in m/s) considered to be realistic.The function is taken to be a linear interpolation of a series of (pressure, speed) points. The pressures and speeds at these points should be specified as keys and values of a JSON-style map. Owing to a bug in the eckit YAML parser, the keys must be enclosed in quotes. For example,
max_speed_interpolation_points: { "0": 900, "100000": 100 }
encodes a linear function equal to 900 m/s at 0 Pa and 100 m/s at 100000 Pa.
rejection_threshold: Maximum fraction of climb rate or speed estimates obtained by comparison with other observations that are allowed to fall outside the allowed ranges before an observation is rejected. Default: 0.5.station_id_variable: Variable storing string- or integer-valued station IDs. Observations taken by each station are checked separately.If not set and observations were grouped into records when the observation space was constructed, each record is assumed to consist of observations taken by a separate station. If not set and observations were not grouped into records, all observations are assumed to have been taken by a single station.
Note: the variable used to group observations into records can be set with the
ObsSpace.ObsDataIn.obsgrouping.group_variableYAML option.
Example:
- filter: Track Check
temporal_resolution: PT30S
spatial_resolution: 20 # km
num_distinct_buddies_per_direction: 3
distinct_buddy_resolution_multiplier: 3
max_climb_rate: 200 # Pa/s
max_speed_interpolation_points: {"0": 1000, "20000": 400, "110000": 200} # Pa: m/s
rejection_threshold: 0.5
station_id_variable: station_id@MetaData
Ship Track Check Filter¶
This filter checks tracks of mobile weather stations, rejecting observations inconsistent with the
rest of the track. It differs from Track Check Filter in that it only considers
inconsistencies in the lat-lon and time dimensions of each observation.
Each track is checked separately. The algorithm starts by performing the following calculations between consecutive observations:
Distances between each observation
The speed between each observation
Angles of the track formed by each triplet of consecutive observations
Various track statistics will be calculated:
The number of track segments (tracks between two consecutive observations) with less than an hour between the two observations.
The number of track segments which exceed a user-defined maximum speed.
The average speed of all track segments which do not fall into categories (1) and (2).
The number of track angles which are greater than or equal to 90 degrees.
If (1), (2), and (4) exceed a percentage of the total observations and the user-defined
early break check setting is enabled, then the track is skipped over, with all
observations left unflagged.
If the filter proceeds, observations are flagged iteratively by removing one of the two
observations forming the fastest segment, until either (a) the segment with the fastest speed is
less than a user-defined max speed (m/s) and the angles formed by this segment with its
adjacent segments are both less than 90 degrees or (b) the segment with the fastest speed is less
than 80 percent of max speed (m/s).
Numerous criteria are applied to choose which of the two observations forming the fastest track
segment should be removed, and track statistic (3) is heavily used in this assessment.
If the percentage of observations rejected rises greater than a
user-defined rejection threshold fraction, the full track is rejected.
The following YAML parameters are supported:
temporal resolution: Assumed temporal resolution of the observations (i.e. absolute accuracy of the reported observation times), used for the speed calculations. Required parameter.spatial resolution (km): Assumed spatial resolution of the observations (in km), i.e. absolute accuracy of the reported positions. Required parameter.max speed (m/s): The maximum speed (in m/s) between any two observations, above which requires the rejection of one of the comprising observations. Required parameter.rejection threshold: The maximum fraction of track observations to be rejected, above which causes the full track to be rejected. Required parameter.early break check: A boolean setting that determines if a track should be skipped (unfiltered) if its count of track statistics (1), (2), and (4) are too large a percentage of the total number of observations. Required parameter.input category: The type of input source. If a static source such as BUOY, track statistic (1) will not be considered in deciding if a track should be skipped. Default: SHPSYN. The supported sources are: LNDSYN, SHPSYN, BUOY, MOBSYN, OPENROAD, TEMP, BATHY, TESAC, BUOYPROF, LNDSYB, and SHPSYB.
Example:
- filter: Ship Track Check
temporal resolution: PT30S
spatial resolution (km): .1
max speed (m/s): 3.0
rejection threshold: 0.5
Met Office Buddy Check Filter¶
This filter cross-checks observations taken at nearby locations against each other, updating their gross error probabilities (PGEs) and rejecting observations whose PGE exceeds a threshold specified in the filter parameters. For example, if an observation has a very different value than several other observations taken at nearby locations and times, it is likely to be grossly in error, so its PGE is increased. PGEs obtained in this way can be taken into account during variational data assimilation to reduce the weight attached to unreliable observations without necessarily rejecting them outright.
The YAML parameters supported by this filter are listed below.
General parameters:
filter variables(a standard parameter supported by all filters): List of the variables to be checked. Currently only surface (single-level) variables are supported. Variables can be either scalar or vector (with two Cartesian components, such as the eastward and northward wind components). In the latter case the two components need to be specified one after the other in thefilter variableslist, with the first component having thefirst_component_of_twooption set to true. Example:filter variables: - name: air_temperature - name: eastward_wind options: first_component_of_two: true - name: northward_wind
rejection_threshold: Observations will be rejected if the gross error probability lies at or above this threshold. Default: 0.5.traced_boxes: A list of quadrangles bounded by two meridians and two parallels. Tracing information (potentially useful for debugging) will be output for observations lying within any of these quadrangles. Example:traced_boxes: - min_latitude: 30 max_latitude: 45 min_longitude: -180 max_longitude: -150 - min_latitude: -45 max_latitude: -30 min_longitude: -180 max_longitude: -150
Default: empty list.
Buddy pair identification:
search_radius: Maximum distance between two observations that may be classified as buddies, in km. Default: 100 km.station_id_variable: Variable storing string- or integer-valued station IDs.If not set and observations were grouped into records when the observation space was constructed, each record is assumed to consist of observations taken by a separate station. If not set and observations were not grouped into records, all observations are assumed to have been taken by a single station.
Note: the variable used to group observations into records can be set with the
obs space.obsdatain.obsgrouping.group_variableYAML option. An example of its use can be found in the Profile consistency checks section above.num_zonal_bands: Number of zonal bands to split the Earth’s surface into when building a search data structure.Note: Apart from the impact on the speed of buddy identification, both this parameter and
sort_by_pressureaffect the order in which observations are processed and thus the final estimates of gross error probabilities, since the probability updates made when checking individual observation pairs are not commutative.Default: 24.
sort_by_pressure: Whether to include pressure in the sorting criteria used when building a search data structure, in addition to longitude, latitude and time. See the note next tonum_zonal_bands. Default: false.max_total_num_buddies: Maximum total number of buddies of any observation.Note: In the context of this parameter,
max_num_buddies_from_single_bandandmax_num_buddies_with_same_station_id, the number of buddies of any observation O is understood as the number of buddy pairs (O, O’) where O’ != O. This definition facilitates the buddy check implementation (and makes it compatible with the original version from the OPS system), but is an underestimate of the true number of buddies, since it doesn’t take into account pairs of the form (O’, O).Default: 15.
max_num_buddies_from_single_band: Maximum number of buddies of any observation belonging to a single zonal band. See the note next tomax_total_num_buddies. Default: 10.max_num_buddies_with_same_station_id: Maximum number of buddies of any observation sharing that observation’s station ID. See the note next tomax_total_num_buddies. Default: 5.use_legacy_buddy_collector: Set to true to identify pairs of buddy observations using an algorithm reproducing exactly the algorithm used in Met Office’s OPS system, but potentially skipping some valid buddy pairs. Default: false.
Control of gross error probability updates:
horizontal_correlation_scale: Encoding of the function that maps the latitude (in degrees) to the horizontal correlation scale (in km).The function is taken to be a piecewise linear interpolation of a series of (latitude, scale) points. The latitudes and scales at these points should be specified as keys and values of a JSON-style map. Owing to a limitation in the eckit YAML parser (https://github.com/ecmwf/eckit/pull/21), the keys must be enclosed in quotes. For example,
horizontal_correlation_scale: { "-90": 200, "90": 100 }
encodes a function varying linearly from 200 km at the south pole to 100 km at the north pole.
Default:
{ "-90": 100, "90": 100 }, i.e. a constant function equal to 100 km everywhere.temporal_correlation_scale: Temporal correlation scale. Default: PT6H.damping_factor_1Parameter used to “damp” gross error probability updates using method 1 described in section 3.8 of the OPS Scientific Documentation Paper 2 to make the buddy check better-behaved in data-dense areas. See the reference above for the full description. Default: 1.0.damping_factor_2Parameter used to “damp” gross error probability updates using method 2 described in section 3.8 of the OPS Scientific Documentation Paper 2 to make the buddy check better-behaved in data-dense areas. See the reference above for the full description. Default: 1.0.
Example:
- filter: Met Office Buddy Check:
filter variables:
- name: eastward_wind
options:
first_component_of_two: true
- name: northward_wind
- name: air_temperature
rejection_threshold: 0.5
traced_boxes: # trace all observations
- min_latitude: -90
max_latitude: 90
min_longitude: -180
max_longitude: 180
search_radius: 100 # km
station_id_variable:
name: station_id@MetaData
num_zonal_bands: 24
sort_by_pressure: false
max_total_num_buddies: 15
max_num_buddies_from_single_band: 10
max_num_buddies_with_same_station_id: 5
use_legacy_buddy_collector: false
horizontal_correlation_scale: { "-90": 100, "90": 100 }
temporal_correlation_scale: PT6H
damping_factor_1: 1.0
damping_factor_2: 1.0
Implementation Notes¶
The implementation of this filter consists of four steps: sorting, buddy pair identification, PGE update and observation flagging. Observations are grouped into zonal bands and sorted by (a) band index, (b) longitude, (c) latitude, in descending order, (d) pressure (if the sort_by_pressure option is on), and (e) datetime. Observations are then iterated over, and for each observation a number of nearby observations (lying no further than search_radius) are identified as its buddies. The size and “diversity” of the list of buddy pairs can be controlled with the max_total_num_buddies, max_num_buddies_from_single_band and max_num_buddies_with_same_station_id options. Subsequently, the PGEs of the observations forming each buddy pair are updated. Typically, the PGEs are decreased if the signs of the innovations agree and increased if they disagree. The magnitude of this change depends on the background error correlation between the two observation locations, the error estimates of the observations and background values, and the prior PGEs of the observations: the PGE change is the larger, the stronger the correlation between the background errors and the narrower the error margins. Once all buddy pairs have been processed, observations whose PGEs exceed the specified rejection_threshold are flagged.
History Check Filter¶
This filter runs the Ship Track Check filter and/or the Stuck Check filter (depending on the observation type) on an auxiliary obs space. The auxiliary obs space is expected to be a superset of the original obs space, with an earlier start time than the assimilation window but the same end time. The equivalent observations to those which were flagged in the auxiliary obs space are then flagged in the original obs space. This filter is motivated by the fact that the Ship Track Check and Stuck Check filters both rely on viewing observations within the context of their surrounding observations. Thus, this filter makes the underlying filters more reliable for observations early in the assimilation window. The filters are run independently: any observations within the assimilation window flagged by either of the sub-filters will be flagged by this filter.
The following YAML parameters are supported:
input category: Surface observation subtype which determines if the ship track check and/or the stuck check filters should be run. Supported options are LNDSYN, SHPSYN, BUOY, MOBSYN, OPENROAD, TEMP, BATHY, TESAC, BUOYPROF, LNDSYB, and SHPSYB. Required parameter.time before start of window: The duration of time before the start of the assimilation window to collect for the history check. This required parameter must be entered in ISO 8601 duration format.ship track check parameters: The options for running the ship track check filter, should the subtype not be LNDSYN or LNDSYB. These must be filled in for the ship track check filter to run. The particular sub-parameters to fill in aretemporal resolution,spatial resolution (km),max speed (m/s),rejection threshold, andearly break check. Please refer to the Ship Track Check filter documentation for additional details on how each of these sub-parameters works. Optional parameter.stuck check parameters: The options for running the stuck check filter, should the subtype not be TEMP, BATHY, TESAC, or BUOYPROF. These must be filled in for the stuck check filter to run. The particular sub-parameters to fill in arenumber stuck toleranceandtime stuck tolerance. Please refer to the Stuck Check Filter documentation for additional details on how each of these sub-parameters works. Optional parameter.obs space: The options used to create the auxiliary obs space that is determined by the observation subtype. A user needs to enter the following fields: name, simulated variables, and obsdatain.obsfile or generate. It additionally may be necessary to specify the distribution as InefficientDistribution. This prevents the observations from distributing to different processors between the original obs space and the auxiliary obs space, which could cause in-window observations flagged in the auxiliary obs space to be left unflagged in the original obs space.station_id_variable: Variable storing string- or integer-valued station IDs. Observations taken by each station are checked separately. Applies to assimilation observation space.If not set and observations were grouped into records when the observation space was constructed, each record is assumed to consist of observations taken by a separate station. If not set and observations were not grouped into records, all observations are assumed to have been taken by a single station.
Example:¶
With the following parameters, the history check filter will be run on the obs space explicitly
simulated, using the generated air temperature values for the stuck check and the lat-lon-dt values
for the ship track check. time before start of window set as 3 hours will cause the
filters to run from 3 hours before the start of the assimilation window (regardless of the time
range present in the auxiliary obs space).
- filter: History Check
input category: 'SHPSYN'
time before start of window: PT3H
filter variables: [air_temperature]
stuck check parameters:
number stuck tolerance: 2
time stuck tolerance: PT2H
ship track check parameters:
temporal resolution: PT1S
spatial resolution (km): 0.001
max speed (m/s): 0.01
rejection threshold: 0.5
early break check: false
station_id_variable:
name: station_id@MetaData
obs space:
name: Ship
distribution: InefficientDistribution
simulated variables: [air_temperature]
generate:
list:
lats: [-37.1, -37.2, -37.3]
lons: [82.5, 82.5, 82.5]
datetimes: [ '2010-01-01T00:00Z', '2010-01-01T01:30Z', '2010-01-01T03:00Z']
obs errors: [1.0]
Variable Assignment Filter¶
This “filter” (it is not a true filter; rather, a “processing step”) assigns specified values to
specified variables at locations selected by the where statement, or at all locations if
the where keyword is not present.
The assigned values can be constants, existing ObsSpace variables or vectors generated by
ObsFunctions. If the variables don’t exist yet, they are created; in this case locations not
selected by the where statement are initialized with missing-value markers.
The values assigned to individual variables are specified in the assignments list in the
YAML file. Each element of this list can contain the following options:
name: Name of the variable to which new values should be assigned. The variable can be from any group except forObsValue(useDerivedObsValueinstead).channels: (Optional) Set of channels to which new values should be assigned.value: Value to be assigned to the specified variable. Exactly one of thevalue,source variableandfunctionoptions must be present.source variable: Variable that should be copied into the destination variable (specified in thenameoption). Exactly one of thevalue,source variableandfunctionoptions must be present.function: An ObsFunction that should be evaluated and assigned to the specified variable. Exactly one of thevalue,source variableandfunctionoptions must be present.type: Type (int,float,stringordatetime) of the variable to which new values should be assigned. This option only needs to be provided if the variable doesn’t exist yet. If this option is provided and the variable already exists, its type must match the value of this option, otherwise an exception is thrown.
It is possible to assign variables or ObsFunctions of type int to variables of type
float and vice versa. No other type conversions are supported.
If the modified variable belongs to the DerivedObsValue group and is a simulated variable,
QC flags previously set to missing are reset to pass at locations where a valid
observed value has been assigned. Conversely, QC flags previously set to pass are reset to
missing at locations where the observed value has been set to missing.
Example 1¶
Create new variables air_temperature@GrossErrorProbability and
relative_humidity@GrossErrorProbability and set them to 0.1 at all locations.
- filter: Variable Assignment
assignments:
- name: air_temperature@GrossErrorProbability
type: float # type must be specified if the variable doesn't already exist
value: 0.1
- name: relative_humidity@GrossErrorProbability
type: float
value: 0.1
Example 2¶
Set air_temperature@GrossErrorProbability to 0.05 at all locations in the tropics.
- filter: Variable Assignment
where:
- variable:
name: latitude@MetaData
minvalue: -30
maxvalue: 30
assignments:
- name: air_temperature@GrossErrorProbability
value: 0.05
Example 3¶
Set relative_humidity@GrossErrorProbability to values computed by an ObsFunction
(0.1 in the southern extratropics and 0.05 in the northern extratropics, with a linear
transition in between).
- filter: Variable Assignment
assignments:
- name: relative_humidity@GrossErrorProbability
function:
name: ObsErrorModelRamp@ObsFunction
options:
xvar:
name: latitude@MetaData
x0: [-30]
x1: [30]
err0: [0.1]
err1: [0.05]
Example 4¶
Copy the variable height@MetaData to geopotential_height@DerivedMetaData.
- filter: Variable Assignment
assignments:
- name: geopotential_height@DerivedMetaData
type: float # type must be specified if the variable doesn't already exist
source variable: height@MetaData
RTTOV 1D-Var Check (RTTOVOneDVar) Filter¶
This filter performs a 1-dimensional variational assimilation (1D-Var) that produces optimal retrievals of physical parameters that describe the atmosphere and surface and on which there is information in the measurement. It takes as input a set of observations (brightness temperatures) and model background fields which are used to initialise the retrieval profile. A retrieval (or analysis) is performed using an iterative procedure that attempts to find the minimum of a cost function that represents the most likely profile vector given the error characteristics of the two data sources.
The elements contained in the retrieval profile depend on the sensitivity of the measuring instruments to atmospheric and surface properties and also what can be modelled with a relatively high degree of accuracy. Most retrieval profiles will consist of atmospheric temperature and humidity, and surface skin temperature, with other possible constituents being liquid and ice water or some other cloud parameter measure, and emissivity parameters.
The filter provides some retrieval parameters to the assimilation which may be missing in the background or insufficiently accurate, such as surface skin temperature, and to filter out observations for which a retrieval could not be performed and thus may be difficult to assimilate in the full variational assimilation.
The filter is a port of the Met Office OPS 1D-Var and makes use of the Fortran RTTOV interface within JEDI. The code is written predominantly in Fortran. Files containing the observation error covariance (R) and the background error covariance (B) are expected as inputs.
This filter requires the following YAML parameters:
BMatrix: path to the b-matrix file.RMatrix: path to the r-matrix file.nlevels: the number of levels used in the retrieval profile.retrieval variables: list of retrieval variables (e.g. temperature etc) which form the 1D-Var retrieval vector (x). This needs to match the b-matrix file.ModOptions: options needed for the observation operator (RTTOV only at the moment).filter variables: list of variables (brightness_temperature) and channels which form the 1D-Var observation vector (y).
The following are optional YAML parameters with appropriate defaults:
ModName: forward model name (only RTTOV at the moment). Default:RTTOV.qtotal: flag for total humidity (qt = q + qclw + qi). If this is true the b-matrix must include qt or the code will abort. If this is false then the b-matrix must not contain qt or the code will abort. Default:false.UseQtSplitRain: flag to choose if rain is included in the non-vapour part of qtotal when split. e.g. qnv = ql + qi + qr. Default:true.UseMLMinimization: flag to turn on Marquardt-Levenberg minimizer otherwise a Newton minimizer is used Default:false.UseJforConvergence: flag to use J for the measure of convergence. Default is comparison of the profile absolute differences to background error multiplied byConvergenceFactor. Default:false.UseRHwaterForQC: flag to use liquid water in the q saturation calculations. Default:true.UseColdSurfaceCheck: flag to reset low level temperatures over sea ice and cold low land. Default:false.Store1DVarLWP: flag to store the liquid water path to the observation database evaluated after convergence of the 1D-Var. Default:false.FullDiagnostics: flag to turn on full diagnostics. Default:false.Max1DVarIterations: maximum number of iterations. Default:7.JConvergenceOption: integer to select convergence option. 1 equals percentage change in cost tested between iterations. Otherwise the absolute change in cost is tested between iterations. Default:1.IterNumForLWPCheck: choose which iteration to start checking the liquid water path. Default:2.MaxMLIterations: the maximum number of iterations for the internal Marquardt-Levenberg loop. Default:7.StartOb: the starting observation number for the main loop over all observations. This has been added for testing to allow a subset of observations in an ObsSpace to be evaluated by the filter. Default:0.FinishOb: the finishing observation number for the main loop over all observations. This has been added for testing to allow a subset of observations in an ObsSpace to be evaluated by the filter. Default:0.ConvergenceFactor: cost factor used when the absolute difference in the profile is used to determine convergence. Default:0.4.CostConvergenceFactor: the cost threshold used for convergence check when cost function value is used for convergence. Default:0.01.EmissLandDefault: the default emissivity value to use over land. Default:0.95.EmissSeaIceDefault: the default emissivity value to use over seaice. Default:0.92.
Example:
- filter: RTTOV OneDVar Check
BMatrix: ../resources/bmatrix/rttov/atms_bmatrix_70_test.dat
RMatrix: ../resources/rmatrix/rttov/atms_noaa_20_rmatrix_test.nc4
nlevels: 70
retrieval variables:
- air_temperature
- specific_humidity
- mass_content_of_cloud_liquid_water_in_atmosphere_layer
- mass_content_of_cloud_ice_in_atmosphere_layer
- surface_temperature
- specific_humidity_at_two_meters_above_surface
- skin_temperature
- air_pressure_at_two_meters_above_surface
ModOptions:
Absorbers: [Water_vapour, CLW, CIW]
obs options:
RTTOV_default_opts: OPS
SatRad_compatibility: false # done in filter
Sensor_ID: noaa_20_atms
CoefficientPath: Data/
filter variables:
- name: brightness_temperature
channels: 1-22
qtotal: true
ModelOb Threshold Filter¶
This filter applies a threshold to a model profile interpolated to the observation height.
The specified model profile variable is linearly (vertical) interpolated to the observation height using the specified model vertical coordinate variable. This is referred to as the “ModelOb”. Note that the ModelOb is not necessarily one of the HofX variables.
The observation height must be in the same coordinate system as that specified for the model vertical coordinate, e.g. both pressure.
The ModelOb is compared against a set of height-dependent thresholds. We supply a vector of threshold values, and a vector of vertical coordinate values corresponding to those thresholds. The coordinate values must be in the same vertical coordinate as the observation, e.g. pressure. The threshold values are then linearly interpolated to the observation height.
The observation is flagged for rejection if the ModelOb lies outside the threshold value according to threshold type - min or max. E.g. if the threshold type is min, then the observation is flagged if ModelOb is less than the interpolated threshold value.
This filter requires the following YAML parameters:
model profile: name of the model profile variable (GeoVaLs).model vertical coordinate: name of the model vertical coordinate variable (GeoVal).observation height: name of the observation height variable to interpolate to.thresholds: vector of threshold values.coordinate values: vector of vertical coordinate values corresponding tothresholds.threshold type:min. ormax.
Example
- filter: ModelOb Threshold
model profile:
name: relative_humidity@GeoVaLs
model vertical coordinate:
name: air_pressure@GeoVaLs
observation height:
name: air_pressure@MetaData
thresholds: [50,50,40,30]
coordinate values: [100000,80000,50000,20000]
threshold type: min
Satwind Inversion Filter¶
This filter is a processing step which modifies the assigned pressure of AMV observations if a temperature inversion is detected in the model profile and defined criteria are met.
The model profile is searched for the presence of a temperature inversion. Where there are multiple temperature inversions, only the lowest one is found. This is intended only for use on low level AMVs, typically below 700 hPa height.
The pressure of the AMV is corrected downwards in height if the following conditions are true:
Originally assigned pressure is greater than or equal to min_pressure (Pa).
AMV derived from IR and visible channels only.
Temperature inversion is present in the model profile for pressures less than or equal to max_pressure (Pa).
In order to be considered significant, the temperature difference across the top and base of the inversion must be greater than or equal to the inversion_temperature (K) value.
Relative humidity at the top of the inversion is less than the rh_threshold value.
AMV has been assigned above the height of the inversion base.
The AMV is then re-assigned to the base of the inversion.
Reference for initial implementation:
Cotton, J., Forsythe, M., Warrick, F., (2016). Towards improved height assignment and quality control of AMVs in Met Office NWP. Proceedings for the 13th International Winds Workshop 27 June - 1 July 2016, Monterey, California, USA.
This filter requires the following YAML parameters:
observation pressure: name of the observation pressure variable to correct.RH threshold: relative humidity (%) threshold value.
The following are optional YAML parameters with appropriate defaults:
minimum pressure: minimum AMV pressure (Pa) to consider for correction. Default:70000.Pa.maximum pressure: maximum model pressure (Pa) to consider. Default:105000.Pa.inversion temperature: temperature difference (K) between the inversion base and top. Default:2.0K.
Example:
- filter: Satwind Inversion Correction
observation pressure:
name: air_pressure@MetaData
RH threshold: 50
maximum pressure: 96000
GNSS-RO 1D-Var Check (GNSSROOneDVar) Filter¶
This filter performs a 1-dimensional variational assimilation (1D-Var) that acts as a quality-control check for GNSS-RO profile data. It finds the optimal set of bending angles based on the background departures from the observations. If these optimal values are too far from the observation, or the minimisation does not converge within a given number of iterations, then the full profile of observations is rejected. Other, smaller, tests are also included.
The bending angle observations are normally stored individually, rather than being kept as a profile. Therefore the profile is constructed using the record number as an identifier for which observations belong to a given profile. These observations are sorted according to their impact parameter (smallest first) and the GeoVaL for the first observation is used to represent the model background values for the whole profile. This filter is currently tied to the Met Office’s bending angle operator for GNSS-RO and thus requires the appropriate inputs for that operator.
This filter requires the following parameters to be set in the yaml:
bmatrix_filename: The file-name of the background-error covariance used.capsupersat: If true calculate saturation vapour pressure with respect to water and ice (below zero degrees), else calculate it with respect to water everywhere.cost_funct_test: The profile is rejected if the final cost-function is larger thancost_funct_testtimes the number of observations.Delta_ct2: The minimisation is considered to have converged if the absolute value of the change in the solution for an iteration, divided by the gradient in the cost-function is less thanDelta_ct2times the number of observations in the profile, divided by 200.Delta_factor: The minimisation is considered to have converged if the absolute change in the cost-function at this iteration is less thanDelta_factortimes either the previous value of the cost-function or the number of observations (whichever is the smaller). That is, the minimisation has converged if:ABS(J_new - J_old) < Delta_factor * min(J_old, nObs)min_temp_grad: Threshold for the minimum temperature gradient before a profile is considered isothermal (units: K per model level). Only applies if pseudo-levels are being used.n_iteration_test: The maximum number of iterations - the profile is rejected if it does not converge in time.OB_test: If the RMS difference between the observations and the background bending angle is greater thanOB_testthen the whole profile is rejected.pseudo_ops: Whether to use pseudo-levels to reduce interpolation errors in the forward model.vert_interp_ops: If true use linear interpolation in ln(pressure), otherwise use linear interpolation in exner.y_test: If an observation is more thany_testtimes the observation error away from the solution bending angle, then the observation (not the whole profile) is rejected.
Example
Model Best Fit Pressure Filter¶
This filter calculates the model best-fit pressure and flags cases where this estimate is poorly constrained. Optionally, it can output the best-fit eastward and northward wind vectors, which are the model background winds interpolated to the model best-fit pressure.
The model best-fit pressure is defined as the model pressure (Pa) with the smallest vector difference between the AMV and model background wind, but additionally is not allowed to be lower than the threshold specified in the top pressure parameter. Vertical interpolation is performed between model levels to find the minimum vector difference.
Checking if the pressure is well-constrained:
Remove any winds where the minimum vector difference between the AMV u (eastward_wind) and v (northward_wind) and the background column u and v is greater than the threshold specified in the upper vector diff parameter. This check aims to remove cases where there is no good agreement between the AMV and the winds at any level in the background wind column.
Remove any winds where the vector difference is less than the lower vector diff anywhere outside the band of width 2 * pressure band half-width centered around the best-fit pressure level. This aims to catch cases where there are secondary minima or very broad minima. In both cases the best-fit pressure is not well constrained.
This filter accepts the following YAML parameters:
observation pressure: Name of the observation pressure variable. Required parameter.model pressure: Name of the model pressure variable. Required parameter.top pressure: Minimum allowed pressure region. Default:10000.Pa.pressure band half-width: Pressure band, for calculating constraint. Default:10000.Pa.upper vector diff: Max vector difference allowed, for calculating constraint. Default:4.m/s.lower vector diff: Min vector difference allowed, for calculating constraint. Default:2.m/s.tolerance vector diff: Tolerance for vec_diff comparison. Default:1.0e-8m/s.tolerance pressure: Tolerance for pressure comparison. Default:0.01Pa.calculate bestfit winds: To calculate best-fit winds by linear interpolation. Output stored in “model_bestfit_eastward_wind@DerivedValue” and “model_bestfit_northward_wind@DerivedValue”. Default:false
Example
- filter: Model Best Fit Pressure
observation pressure:
name: air_pressure@MetaData
model pressure:
name: air_pressure_levels@GeoVaLs
top pressure: 10000
pressure band half-width: 10000
upper vector diff: 4
lower vector diff: 2
tolerance vector diff: 1.0e-8
tolerance pressure: 0.01
calculate bestfit winds: true
Process AMV QI¶
This “filter” (it is not a true filter; rather, a “processing step”) converts AMV Quality Index (QI) values stored in the 3-10-077 BUFR template into variables with names corresponding to the wind generating application number.
If not present, new QI variables are created. Created QI variables depend on “wind_generating_application_<number>” and fills them with the values found in “percent_confidence_<number>”.
The wind generating application numbers are associated as below:
Wind generating application number |
QI type |
Variable name |
|---|---|---|
1 |
Full weighted mixture of individual quality tests |
QI_full_weighted_mixture |
2 |
Weighted mixture of individual tests, but excluding forecast comparison |
QI_weighted_mixture_exc_forecast_comparison |
3 |
Recursive filter function |
QI_recursive_filter_function |
4 |
Common quality index (QI) without forecast |
QI_common |
5 |
QI without forecast |
QI_without_forecast |
6 |
QI with forecast |
QI_with_forecast |
7 |
Estimated Error (EE) in m/s converted to a percent confidence |
QI_estimated_error |
This filter accepts the following YAML parameters:
number of generating apps: How many generating application variables to search for. Required parameter.
Example
- filter: Process AMV QI
number of generating apps: 4