IODA Interfaces¶
Background¶
IODA interacts with external observation data on one side and with the OOPS and UFO components of JEDI on the other side (Fig. 1). On the observation data side there exist huge amounts of data, thus creating the need to pare these data down to a manageable size for JEDI during a particular DA run. The primary mechanism for accomplishing this is to filter out all of the observations that lie outside the current DA timing window, and present only that subset to be read into memory during a DA run.
There are many different types of observations that come with a variety of ways that the observation data are organized. To the extent that is feasible, it is desirable to devise a common data organization of which all of these observation types can employ. The memory representation of observation data in IODA has started with a prototype along these lines that successfully places a number of observation types (radiosonde, aircraft, AMSU-A, GNSSRO, plus several more) into a common organization.
At this point, we have a prototype architecture defined for the handling of files containing observation data (Fig. 4).
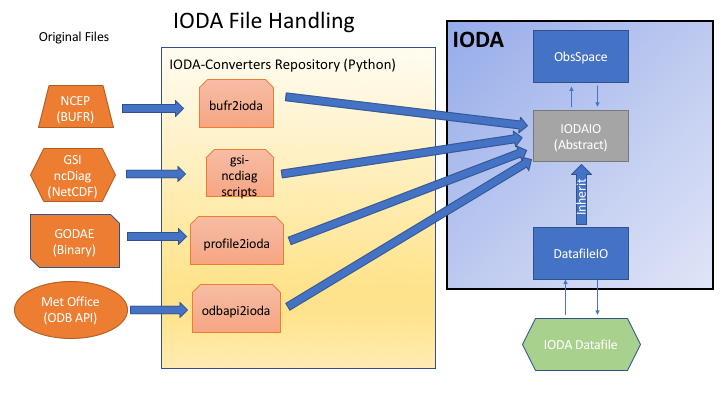
Fig. 4 IODA file handling¶
The intent of this architecture is to enable the use of one IODA file reader/writer implementation, namely the IodaIO class in Fig. 4. Using the single IodaIO class will make future maintenance much simpler, especially since we have not yet settled on the particular file format to use for the IODA Datafile piece.
A first pass implementation of this architecture has been created in the ioda-converters github repository. This implementation is not quite in the form of the prototype architecture, but is evolving toward that goal. Currently, we are using netcdf for the IODA Datafile format (subject to change) and we have a common netcdf writer in the ioda-converters with a collection of readers for the various observation data file formats. Work is in progress to evolve the current implementation to the prototype architecture.
A prototype interface, using a common data organization (Fig. 5), has been defined for access to observation data from the JEDI components OOPS and UFO.
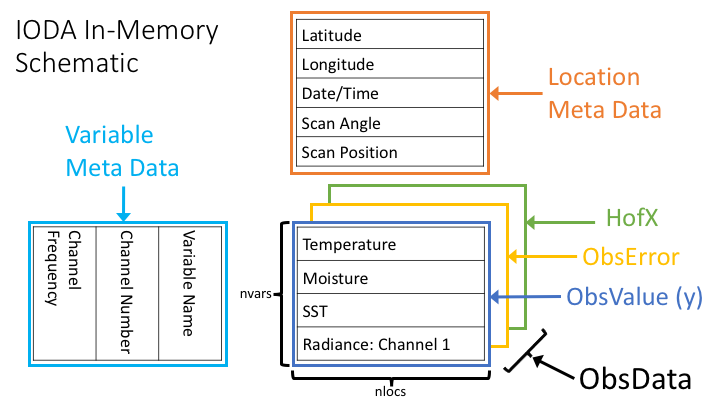
Fig. 5 Schematic view of the IODA in-memory representation¶
Central to this scheme are the 2D arrays holding the observation data quantities (ObsValue, ObsError, HofX in Fig. 5). Each row of the ObsData array holds a particular vector of observation-related data. The length of each row is equal to the number of unique locations (nlocs), (x,y,z,t) or (x,y,t) tuple values, and the number of rows corresponds to the set of available observation variables (nvars). Note that an ObsVector can be constructed using a subset of the variables (rows) in the ObsData arrays. In the case of satellite data, the rows correspond to individual instrument channels.
Currently, the elements in an ObsData array are either floating point numbers or integers (e.g., QC marks). As more complex observation types come on board, the idea is to enhance the ObsData array so that each element can be a more complex data type. For example, each element could be a vector, or a higher rank array of numbers. In the case of using vectors for each element, the ObsData array effectively becomes a three-dimensional array.
In addition to the ObsData arrays, two more arrays are added that contain meta data. The Location Meta Data array (Fig. 5) contains rows, of length nlocs, corresponding to meta data oriented by location. Examples of Location Meta Data are quantities that describe each location such as Latitude, Longitude, Date/Time, and descriptive quantities associated with locations such the Scan Angle of an satellite-borne instrument.
The Variable Meta Data array is analogous to the Location Meta Data array, except that it holds meta data associated with the variables in the ObsData arrays. Examples include the variable names, and in the case of some instruments, channel numbers and channel frequencies.
A first pass implementation of this interface has been implemented in the ioda github repository. This implementation is entirely in C++ and is successfully handling a small set of observation types including radiosonde, aircraft, ADO, AMSU-A, GNSSRO and Marine (SST, sea ice thickness and fraction, etc.) test cases.
Interfaces to External Observation Data¶
These interfaces are under heavy development and currently not well defined. We are working with data providers to get these interfaces more clearly defined over the next one to two months.
Data Tanks¶
The means for converting observation data in the external data tanks into files that IODA can read are being handled by a number of scripts and programs in the ioda-converters github repository. This code is relatively new and under active development. The goal is to organize the code into specific readers for each data tank format, all tied into a general IODA file writer, namely the IodaIO abstract interface class shown in Fig. 4. Organizing this way will allow us to experiment with different file formats, for the IODA datafile piece (Fig. 4), with minimal interference for the clients of the IodaIO class.
Diagnostic Files¶
At this point, we are actively investigating the best option for the diagnostic file type and data organization in IODA. We are using the same data organization as the IODA input file which currently is a netcdf file. As the requirements for downstream diagnostic tools get clarified, the file type and data organization are subject to change.
The creation of the diagnostics file (IODA output) is specified in the YAML configuration.
The ObsDataOut keyword along with the obsfile sub-keyword are used to request that a diagnostics file be created.
This occurs during the destructor of the ObsSpace object, which is near the end of the DA run.
Currently, the entire contents of the memory store is written into the output file, and there are plans to allow for the selection of a subset of the memory store via the YAML configuration.
If the DA run is using multiple process elements, one file per element is created using just the observation data associated with that element. The file names get the process element rank number appended to them which avoids file collisions. This scheme is okay for testing with small datasets, but could be problematic when using a large number of process elements. This will need to be addressed before getting into operational sized DA runs.
Example Radiosonde YAML¶
The following is the YAML for the UFO test “test_ufo_radiosonde_opr”.
window begin: 2018-04-14T21:00:00Z
window end: 2018-04-15T03:00:00Z
observations:
- obs space:
name: Radiosonde
obsdatain:
obsfile: Data/sondes_obs_2018041500_m.nc4
obsdataout:
obsfile: Data/sondes_obs_2018041500_m_out.nc4
simulated variables: [air_temperature]
obs operator:
name: VertInterp
vertical coordinate: air_pressure
geovals:
filename: Data/sondes_geoval_2018041500_m.nc4
vector ref: GsiHofX
tolerance: 1.0e-04 # in % so that corresponds to 10^-3
linear obs operator test:
iterations TL: 12
tolerance TL: 1.0e-9
tolerance AD: 1.0e-11
Under the obs space.obsdataout.obsfile specification, the output file is requested to be created in the path: Data/sondes_obs_2018041500_m_out.nc4.
If there is only one process element, then the output will appear in the file as specified.
However, if there are 4 process elements, then the output will appear in the following four files:
Data/sondes_obs_2018041500_m_out_0000.nc4
Data/sondes_obs_2018041500_m_out_0001.nc4
Data/sondes_obs_2018041500_m_out_0002.nc4
Data/sondes_obs_2018041500_m_out_0003.nc4
More details about constructing and processing YAML configuration files can be found in JEDI Configuration Files: Content and Configuring JEDI.
Interfaces to other JEDI Components¶
These interfaces have a much clearer definition than the interfaces to external observation data (see Interfaces to External Observation Data above). However, these are still new and will likey need to evolve as more observation types are added to the system.
OOPS Interface¶
OOPS accesses observation data via C++ methods belonging to the ObsVector class.
The variables being assimilated are selected in the YAML configuration using the simulated variables sub-keyword under the obs space keyword.
In the radiosonde example above, one variable “air_temperature” is being assimilated.
In this case, the ObsVector will read only the air_temperature row from the ObsData table and load that into a vector.
The ObsVector class contains the following two methods, read() for filling a vector from an ObsData array in memory and save() for storing a vector into an ObsData array.
// Interface prototypes
void read(const std::string &);
void save(const std::string &) const;
The
std::stringarguments are the names of the ObsData array that is to be accessed.
Following is an example of reading into an observation vector.
Note that the ObsVector object yobs_ has already been constructed which included the allocation of the memory to store the observation data coming from the read() method.
// Read observation values
Log::trace() << "CostJo::CostJo start" << std::endl;
yobs_.read("ObsValue");
Log::trace() << "CostJo::CostJo done" << std::endl;
Here is an example of saving the contents of an observation vector, H(x), into an ObsData array. The ObsVector object yobs is constructed in the first line, and the third line creates an ObsData array called “hofx” and stores the vector data into that ObsData array.
// Save H(x)
boost::scoped_ptr<Observations_> yobs(pobs->release());
Log::test() << "H(x): " << *yobs << std::endl;
yobs->save("hofx");
UFO Interface¶
UFO accesses observation data via Fortran functions and subroutines belonging to the ObsSpace class. ObsSpace is implemented in C++ and a Fortran interface layer is provided for UFO. The following three routines are used to access observation data, and unlike the ObsVector methods in the OOPS Interface above, access is available to ObsData arrays and all Meta Data arrays. Reasons to access ObsData arrays from UFO would be for debugging purposes or for storing results, such as H(x), for post analysis. Typically, only meta data are used in the actual H(x) calculations.
! Interface prototypes
integer function obsspace_get_nlocs(obss)
subroutine obsspace_get_db(obss, group, vname, vect)
subroutine obsspace_put_db(obss, group, vname, vect)
The
obssarguments are C pointers to ObsSpace objects.- The
grouparguments are names of the ObsData arrays holding the requested variable E.g., “HofX”, “MetaData”
- The
- The
vnamearguments are names of the requested variable (row) E.g., “air_temperature”, “Scan_Angle”
- The
- The
vectargument is a Fortran array for holding the data values The client (caller) is responsible for allocating the memory for the
vectargument
- The
Following is an example from the CRTM radiance simulator, where meta data from the instrument are required for doing the simulation.
! Get nlocs and allocate storage
nlocs = obsspace_get_nlocs(obss)
allocate(TmpVar(nlocs))
! Read in satellite meta data and transfer to geo structure
call obsspace_get_db(obss, "MetaData", "Sat_Zenith_Angle", TmpVar)
geo(:)%Sensor_Zenith_Angle = TmpVar(:)
call obsspace_get_db(obss, "MetaData", "Sol_Zenith_Angle", TmpVar)
geo(:)%Source_Zenith_Angle = TmpVar(:)
call obsspace_get_db(obss, "MetaData", "Sat_Azimuth_Angle", TmpVar)
geo(:)%Sensor_Azimuth_Angle = TmpVar(:)
call obsspace_get_db(obss, "MetaData", "Sol_Azimuth_Angle", TmpVar)
geo(:)%Source_Azimuth_Angle = TmpVar(:)
call obsspace_get_db(obss, "MetaData", "Scan_Position", TmpVar)
geo(:)%Ifov = TmpVar(:)
call obsspace_get_db(obss, "MetaData", "Scan_Angle", TmpVar) !The Sensor_Scan_Angle is optional
geo(:)%Sensor_Scan_Angle = TmpVar(:)
deallocate(TmpVar)
An example for storing the results of a QC background check is shown below. Note that the storage for “flags” has been allocated and “flags” has been filled with the background check results prior to this code.
write(buf,*)'UFO Background Check: ',ireject,trim(var),' rejected out of ',icount,' (',iloc,' total)'
call fckit_log%info(buf)
! Save the QC flag values
call obsspace_put_db(self%obsdb, self%qcname, var, flags)